A aritmética binária é um conceito básico em programação que atua como a espinha dorsal para sistemas de computador, redes e processamento de dados.
Entender números binários ou suas soluções é importante para programadores. Se eles querem escrever código eficiente, depuração eficaz e otimizar algoritmos.
Ao ler este guia, os programadores exploraram o conceito de aritmética binária , sua importância, operações básicas e o conceito crítico de complemento de dois. No final deste guia, eles saberão como lidar com esse processo.
O que é aritmética binária?
A aritmética binária ajuda a resolver operações matemáticas usando o sistema numérico binário. Ela é baseada em dois dígitos 0 e 1. Na aritmética binária, cálculos como adição, subtração, multiplicação e divisão seguem regras semelhantes às da aritmética decimal, mas usam a base 2 em vez de 10.
Elas são usadas para resolver as diferentes operações binárias. A seguir, confira uma breve visão geral de como elas funcionam e dicas para operá-las.
Operações aritméticas binárias básicas
As operações binárias permitem que o computador manipule cálculos no nível mais fundamental. Isso faz com que os programadores trabalhem efetivamente para código de baixo nível ou otimização de desempenho.
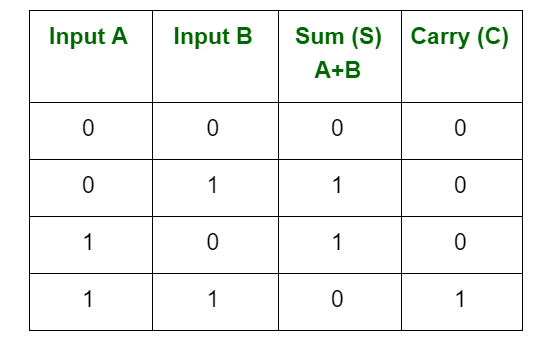
Adição binária:
Esta operação básica é semelhante à adição decimal, mas com apenas dois dígitos: 0 e 1. As regras para adição binária são:
Exemplo:
1010
+ 0101
1111
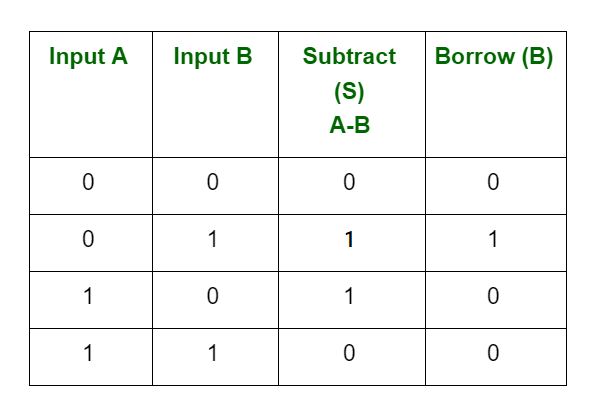
Subtração binária:
A subtração binária é semelhante à subtração decimal. Se o número de subtração for pequeno, então pegue emprestado um número do próximo número à direita. Abaixo estão as 4 regras básicas usadas para subtração binária:
Nota : 0 – 1 = 1 (com um empréstimo do próximo bit mais alto)
A subtração geralmente envolve um complemento de dois, onde números negativos são representados usando binário. Neste sistema, a subtração pode ser transformada em adição de números negativos.
Exemplo:
1010
– 0101
101
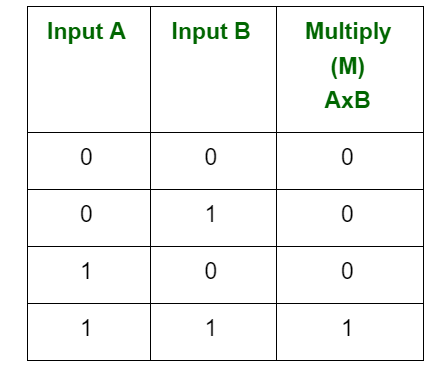
Multiplicação Binária
A multiplicação de binário é direta. Ela envolve apenas multiplicar por 0 e 1. Abaixo estão as regras para isso:
Exemplo:
1010
x 0101
1010
0000x
1010xx
0000xxx
110010
Divisão Binária
Segue um processo similar à divisão longa em decimal. Divide números binários bit a bit.
Exemplo:
1100 ÷ 10
O resultado é 110, equivalente a dividir 12 por 2 em decimal, dando um resultado de 6.
Complemento de dois e aritmética binária
Em programação, o complemento de dois é o método mais comum para representar números negativos. Ele simplifica o processo de adição e subtração de números com sinal.
Existem duas formas de representação:
Números positivos são representados da mesma forma que inteiros sem sinal.
Números negativos representam o complemento de dois do valor positivo correspondente.
Você pode calcular o número binário para complemento de dois seguindo esses passos:
Inverta todos os bits (mude 0 para 1 e 1 para 0).
Adicione 1 ao resultado.
Este método permite calcular números positivos e negativos de forma rápida e fácil.
Alternativamente, utilize a calculadora complemento de 2. Assim, ele ajuda a resolver três tipos de dígitos, cadeias de números positivos ou negativos (como decimal, binário e hexadecimal). Proporciona resultados, simplesmente, ingressando valores nos campos de entrada proporcionados.
Importância da representação do complemento de dois na aritmética binária
O complemento de 2 ajuda na representação de expressões aritméticas. Como também torna a solução fácil e possui vários benefícios na aritmética binária. Alguns deles estão a seguir:
Operações aritméticas unificadas
O complemento de dois adiciona e subtrai números positivos ou negativos com um método especial. Isso torna mais fácil projetar hardware de computador, já que não precisamos de circuitos separados para diferentes tipos de números.
Representação única do zero
No complemento de 2, há apenas uma maneira de representar zero (000). Isso evita confusão e torna o cálculo mais claro.
Faixa de valor eficiente
Esta vantagem é uma das melhores de todas, o complemento de dois usa os bits disponíveis sabiamente e melhora o uso dos números. Por exemplo:
Em um sistema de 8 bits, ele pode representar números de -128 a 127.
Isso fornece um intervalo eficiente para números positivos e negativos.
Aplicações da aritmética binária na programação
A aritmética binária é importante em programação e sistemas digitais. Aqui estão algumas aplicações-chave onde a aritmética binária desempenha um papel crucial:
Representação de dados
Uma das aplicações mais importantes da aritmética binária é a formatação de dados. Ela armazena e processa todos os dados como texto, imagens e vídeos em formato binário. Cada pedaço de informação é representado como uma série de dígitos binários (0s e 1s).
Design lógico digital
A aritmética binária forma a base para projetar circuitos digitais. Portas lógicas (AND, OR, NOT) operam em entradas binárias para produzir saídas baseadas em regras aritméticas binárias.
Detecção e correção de erros
É importante em algoritmos de detecção de erros, como checksums e bits de paridade. Esses métodos ajudam a garantir a integridade dos dados durante a transmissão, identificando erros que podem ocorrer em dados binários.
Redes de computadores
Em redes, a aritmética binária é usada para calcular endereços IP e máscaras de sub-rede. As operações binárias ajudam a determinar a porção de rede e a porção de host de um endereço.
Aprendizado de máquina
Representações binárias são usadas em vários algoritmos de machine learning para codificação e processamento de dados. Entender a aritmética binária ajuda a otimizar o desempenho ao lidar com grandes conjuntos de dados.
Conclusão
A aritmética binária é a base dos sistemas de computador. Ela envolve a execução de operações matemáticas usando 0s e 1s. Entender a aritmética binária é crucial para que os programadores escrevam códigos eficientes, apurem efetivamente e otimizem algoritmos.
Complemento de dois é um conceito-chave para representar números negativos em binário. A calculadora de complemento de dois provou ser uma ferramenta valiosa para resolver os diferentes números binários de forma eficiente. Ao dominar problemas aritméticos binários, os programadores entendem facilmente como os computadores processam dados e tomam decisões conscientes em seu trabalho de programação.
O que faz um programador e como se destacar no mercado? Se essas são as suas dúvidas, leia este artigo com dicas incríveis de mercado e qualificação.
O programador é um profissional extremamente requisitado no mercado de TI, sendo especializado em criar e desenvolver softwares e aplicativos. Entre as linguagens trabalhadas por esse profissional podemos destacar o html, java, c++ que são utilizados para criar os comandos nos programas.
Trata-se de um mercado extremamente aquecido, onde os profissionais que desejam ter sucesso nesta área precisam investir pesado em cursos técnicos, graduações e pós-graduações em tecnologia da informação. Acompanhe esse artigo e saiba como atuar neste mercado e se destacar.
Entenda o que faz um programador
Um programador ou desenvolvedor é responsável por escrever códigos que se tornarão comandos de programação. Entre as linguagens de programação mais usadas para escrever esses códigos estão o JavaScript, jQuery, PHP, Python, Ruby, HTML, CSS e APIs.
Através destas linguagens o programador poderá desenvolver ou aperfeiçoar sites, aplicativos, programas de computador, sistemas de empresas entre outros. Trata-se de um profissional altamente requisitado no mercado. As possibilidades de atuação são imensas, pois a tecnologia se renova constantemente.
Entenda o que é preciso para trabalhar como programador
Se você está de olho nesta área de atuação, saiba que vai precisar estudar muito. Conhecimentos técnicos e teóricos são extremamente necessários, porém um alto conhecimento prático pode definir o seu posicionamento no mercado. Invista em uma boa formação.
Atualmente, é possível encontrar cursos livres de programação que duram poucos meses focados em linguagens específicas como java ou PHP. No entanto, se você deseja ser um profissional completo, precisará investir em uma boa graduação.
Há também cursos técnicos focados na prática que podem te dar o pontapé inicial para entrar no mercado. Uma vez inserido no setor, você terá condições financeiras para ampliar a sua formação.
Oportunidades de programação no exterior
O mercado de trabalho para programadores no exterior nunca esteve tão promissor. No entanto, para conquistar uma vaga torna-se necessário se destacar frente aos recrutadores. Entre as estratégias assertivas estão a participação em feiras de contratação e palestras.
Dentro do seu planejamento você deve ficar atento também a questões relacionadas à documentação como passaporte, vistos e permissões necessárias para trabalhar no país desejado.
Tempo de duração de uma faculdade de programação
Em média, a duração de um bom curso de graduação é de 4 anos. Porém conforme dito anteriormente existem excelentes cursos técnicos com duração de 2 anos, ideal para o programador que precisa focar na prática e entrar no mercado o quanto antes.
Se você deseja se aprofundar ainda mais e ampliar as suas oportunidades no setor, principalmente em áreas de gestão de TI, invista em cursos de pós-graduação que tem duração média de um a dois anos.Entre os melhores cursos de pós-graduação em programação podemos destacar;
Engenharia de Software;
Gestão em Tecnologia da Informação;
Análise e Desenvolvimento de Sistemas em Java;
Big Data e Analytics;
Business Intelligence (BI);
Engenharia de software;
Aplicativos móveis;
Desenvolvimento de jogos.
03 melhores faculdades de Ciência da Computação
Para ser um cientista da computação, é preciso realizar uma graduação. Existem várias faculdades no Brasil que ministram essa faculdade, porém, algumas delas são melhores para te entregar tudo o que você precisa saber para conseguir fazer o que um programador faz. Entre as faculdades, 3 são as melhores. Confira a seguir!
Centro Universitário Facvest (unifacvest)
Com sede situada em Santa Catarina, o Centro Universitário Facvest fornece um curso de Ciências da Computação muito bom. Porém, possui cursos presenciais e EAD, então, possui polos de ensino em vários estados do Brasil, então você pode estudar Ciências da Computação na Unifacvest independentemente de você morar ou não em Santa Catarina.
O curso possui material didático impresso e produzido por professores específicos da área. Além disso, é feito com videoaulas online. Ambos os recursos são disponibilizados na plataforma do curso.
Em 4 anos você aprenderá tudo o que um programador faz, e, assim, poderá se destacar no mercado de trabalho, com mensalidades super acessíveis!
Universidade de Santa Cruz do Sul (unisc)
Também sediada no sul do país, porém a Unisc é no Rio Grande do Sul. Para aprender o que um programador faz e receber um diploma para comprovar que sabe fazer, estudando na Unisc, você poderá estudar somente de modo presencial.
O curso é muito bom e a infraestrutura da faculdade também.
Universidade Estadual do Oeste do Paraná (unioeste)
O curso da Unioeste vem desde 1995 e tem duração mínima de 4 anos, sendo a máxima de 7 anos. A Unioeste possui boa avaliação no MEC e a grade do curso é muito boa, te entregando tudo o que você precisa aprender para fazer o que um programador faz.
Independentemente de qual das três faculdades você escolher, sua formação será de alta qualidade, te possibilitando se destacar no mercado.
Mercado de trabalho na área de programação
Atualmente tudo gira em torno de programas e softwares. Os sistemas estão presentes na indústria, na agropecuária, no sistema financeiro, no entretenimento e em vários outros setores.
Nunca se precisou tanto de bons programadores como hoje. O mercado está extremamente aquecido. Para você ter uma ideia, o mercado nacional de serviços de TI cresceu cerca de 4% em 2020 em relação a 2019, segundo um estudo da IDC Brasil.
Faixa salarial para um programador
É um mercado fantástico, onde os salários são muito atrativos e novas vagas são abertas constantemente. Uma pesquisa realizada pelo site de empregos Catho mostrou que um programador ganha em média R$2.461,00. Porém, esse valor pode variar conforme a área de atuação do programador, acompanhe:
Programador Web: R$ 2.230,00;
Programador PHP: R$ 2.540,00;
Programador Java: R$ 3.240,00;
Programador C++: R$ 3.315,00;
Programador Visual Basic: R$ 2.800,00;
Programador .NET: R$ 3.440,00;
Programador de Jogos: R$ 1.430,00
Programador de Sharepoint: R$ 6.970.00
Desafios e barreiras no desenvolvimento de softwares
O desenvolvimento de softwares, apesar de extremamente importante para os avanços tecnológicos, enfrenta uma série de desafios que dificultam e retardam esse processo. Entre as principais barreiras para o desenvolvimento de softwares, destacam-se:
Limitação de recursos financeiros;
Custos de infraestrutura;
Necessidade de correções e consertos em trabalhos já realizados;
Falha de comunicação entre desenvolvedores e fornecedores;
Complexidade dos processos;
Modificações e imprevistos durante o desenvolvimento;
Análise equivocada de requisitos dos clientes;
Usabilidade do software, pois se ele for difícil de ser utilizado, o cliente não aprovará.
Programador: quanto cobrar por trabalho freelancer
O trabalho freelancer tem se tornado cada vez mais frequente em meio aos profissionais, e essa realidade também ocorre no setor da programação. Porém, um problema muito comum enfrentado pelos trabalhadores é a definição do valor a ser cobrado pelas atividades freelancer.
Se você está pensando em trabalhar nessa modalidade, precisa estar preparado para definir quanto irá cobrar dos seus clientes. Para isso, você deve, antes de tudo, estabelecer quanto quer ganhar como programador e quais serão os seus custos (impostos, custos fixos, serviços terceirizados, imprevistos e etc).
Assim, será possível entender a sua média de salário e, consequentemente, quanto precisará cobrar. A melhor maneira de estabelecer preços é a partir das horas trabalhadas. Então, para realizar o cálculo, some o seu salário desejado e os seus custos e, depois, divida o resultado pela quantidade de horas gastas com o serviço. Dessa forma, você encontrará o valor adequado para a cobrança!
5 Profissões relacionadas a programação
Após se tornar bacharel em Ciência da Computação, a área de atuação que o seu diploma te fornecerá será muito ampla! Aqui, você conhecerá 5 das profissões que você poderá seguir depois de se formar em Ciência da Computação. Confira!
Engenheiro de software
Ser Engenheiro de Software pode ser uma das respostas para a pergunta “ o que um programador faz?”. O profissional é o responsável por desenvolver os programas de computador, assim como os aplicativos e outros tipos de interfaces de navegação digital.
Essa área está em grande expansão, então o mercado tem absorvido muitos profissionais. Portanto, será difícil ser um engenheiro de software e ficar desempregado!
Quanto ao financeiro, os salários dos Engenheiros de Software passam, tranquilamente, dos cinco mil reais. Além disso, o profissional também pode trabalhar administrando projetos da área, em vez de colocar a mão na massa no processo de desenvolvimento em si.
Analista de sistemas
Se você se formar em Ciências da Computação, também poderá ser um analista de sistemas. O profissional será o responsável por desenvolver e controlar os sistemas utilizados pela empresa na qual ele trabalha.
Basicamente, ele é a pessoa que analisará e testará a eficácia dos programas utilizados, propondo e realizando melhorias. Essa análise é feita com base no software, no hardware e na experiência do usuário que, inclusive, é um fator muito importante para medir a qualidade de um sistema operacional.
Assim como várias das outras profissões na área da tecnologia, a Análise de Sistemas está em expansão e poderá ser uma boa decisão tomada por você. Além disso, os salários são muito bons, com médias que giram em torno dos 4 mil reais.
Arquiteto de redes de informática
Dentre as profissões daqui listadas, essa é uma das que mais traz retorno financeiro. O arquiteto de redes é o responsável por otimizar os sistemas de um empresa, realizando as instalações necessárias como modems, hardwares e outros softwares.
Para esses profissionais, a média salarial passa dos 18 mil reais. Afinal, grandes responsabilidades no trabalho geram bons retornos no seu bolso!
Programador de jogos digitais
Se tem uma área que cresce a cada dia são os jogos digitais. Não só no mundo jovem, mas também entre os adultos mais antenados, os jogos digitais são uma grande febre que cresce em níveis antes inimagináveis.
Com histórias emocionantes e envolventes e gráficos de tirar o fôlego, os jogadores, sejam dos vídeo games ou dos mobiles, se encantam com cada uma das novidades lançadas. Por isso, ser um programador de jogos digitais é quase que garantia de sucesso. É claro que, para isso, você precisa saber bem o que um programador faz e desenvolver as tarefas com maestrias.
O programador é o responsável por pegar a história, as imagens e o roteiro, que geralmente são criados pelo designer, e colocar em ação, ou seja, ele é quem faz a produção se tornar, verdadeiramente, um jogo digital.
Como a área está em expansão contínua, o salário também atualmente, as médias giram em torno dos 8 mil reais.
Programador web.
O que faz um programador de jogos digitais você já sabe. Mas, o que faz um programador web?
Bom, esse profissional é responsável por dar vida aos sites e plataformas que acessamos por meio da internet e que são armazenados em servidores da Web.
Como o número de sites no Brasil e no mundo só cresce, é praticamente impossível que a profissão perca em ascensão. Se você quer saber mais sobre sites e tecnologias voltadas a esse ramo, você pode ler nosso texto sobre os sites PWA!
Dicas para se destacar no mercado de programação
Quando você observa os valores acima pode pensar que para se dar bem neste setor você deve se especializar em um tipo de programação. Desta forma, você iria investir todo o seu tempo e dinheiro em apenas uma linguagem. Isso pode ser um tiro no pé. Isso porque a tecnologia muda e se desenvolve o tempo todo e pode acontecer que a tecnologia que você se especializou perca mercado para outras inovações. O ideal é que você tenha um bom conhecimento em todas as linguagens.
Outra dica boa para você se destacar no mercado de TI é entender que cada ramo de negócio está mais propenso a trabalhar com um tipo de linguagem.
Neste contexto, o programador não precisa somente programar, mas entender o segmento empresarial e como a tecnologia pode impulsionar os negócios.
Competências de um bom programador
Sim, existem competências que são primordiais para esse profissional. Ter um raciocínio lógico aguçado é um deles, porém esse profissional também precisa ter uma capacidade de comunicação incrível,pois irá precisar debater ideias e propor soluções para o requisito de melhorias.
Inteligência emocional também é muito importante, pois precisará saber lidar o tempo todo com equipes e lideranças. Simpática e controle emocional dará a você resultados efetivos.
Dicas de como iniciar na área de programação
A maior parte dos programadores começaram na área conhecendo melhor as distintas linguagens de programação. E é quase unânime que a linguagem em Python é a mais recomendada para quem conhece pouco.
Essa linguagem possui diretrizes mais simples de desenvolvimento e com ela podemos desenvolver a sintaxe próxima da linguagem humana. Muitos profissionais já desenvolvem programas básicos em 6 meses sem nem ter se graduado.
Empresas que mais contratam programadores
Em pouquíssimos anos toda empresa precisará de um profissional programador, seja contratado ou terceirizado. Esta já é uma realidade em empresas como Google, Twitter, Meta e outros.
Mas em qualquer lugar do mundo, o profissional programador se deparará com empresas ligadas à segurança da informação. Estas são as que mais contratam no mundo todo.
Saiba o que faz um programador iniciante
Para um programador iniciante autodidata ou até recém formado, o comum é o desenvolvimento de apps e sites empresariais. É um serviço bastante buscado e que paga bem.
Contudo não é uma área comum para ser contratado. Em sua grande maioria, os profissionais são autônomos ou trabalham para agências especializadas.
Saiba o que faz um programador para trabalhar em casa
Quem trabalha com tecnologia vai perceber que atualmente a quantidade massiva de vagas são para home office ou adotam o sistema híbrido (alguns dias em casa, alguns dias na empresa). Então não é tão incomum conseguir emprego para desenvolvedor home office.
Agora, as áreas que são mais voltadas para a TI e que precisam estar próximas do servidor da empresa e do núcleo de dados, não tem outra, é preciso que o profissional esteja 100% trabalhando presencialmente.
Dicas de como conseguir um trabalho de programador no exterior
A grande vantagem de trabalhar como programador é que você pode atuar em qualquer lugar do mundo, sem sair de casa. A adoção do trabalho home-office permite atuar no mercado em qualquer hora do dia e de qualquer local.
Por isso mesmo é comum conseguir clientes fora do seu país de origem. Mas para isso, é preciso que ao menos o inglês esteja afiado.
Mas para quem deseja mudar de país a história é um pouco mais complexa. Para isso é necessário:
Se forma em uma àrea da programação: muitos países exigem diploma para conseguir visto para trabalhar;
Fluência em principalmente inglês e claro, na língua oficial do país que você deseja morar;
Experiência é essencial. Em países de primeiro mundo a concorrência é gritante, é preciso se especializar a fundo na sua área;
Networking é outro ponto que fará as empresas te notarem. O LinkedIn é a melhor ferramenta para isso. Peça a amigos que façam recomendações e busque empresas interessadas para seguir;
Procure sites que oferecem vagas no exterior, como o próprio LinkedIn mas também o LandingJobs (Europa), Hired (Europa), Glassdoor (mundo todo), Indeed (mundo todo) e Dice (EUA).
Saiba o que faz um programador para se destacar no mercado
Embora o mercado de programação no Brasil ainda não esteja a todo vapor, no exterior você nota que a demanda é muito grande e a concorrência também. Dessa maneira, é importante se destacar tanto no Brasil quanto para quem quer trabalhar no exterior.
E duas coisas que é preciso conhecer a fundo é o inglês e também dominar diferentes linguagens de programação. Estas duas coisas juntas te levarão longe. Mas ainda assim, não deixe de desenvolver tanto suas hard skills quanto suas soft skills.
Saiba quanto tempo levar para se formar na área de programação
Um programador leva em média 4 anos para se formar. Mas ainda, ao menos no Brasil, não existe apenas a graduação em programação. Análise de Sistemas e Tecnologia da Informação são alguns cursos recomendados para programadores.
Mas vale lembrar que uma grande parte dos desenvolvedores são autodidatas, ou seja, aprenderam o ofício por conta própria com base em mini-cursos virtuais, fóruns e com a ajuda da comunidade online. Em algumas áreas em menos de um ano já é possível desenvolver o básico. Contudo, é preciso frisar que a graduação é necessária para aprender o conceito, teoria e entender como o algoritmo baseado em álgebra funciona. E estes detalhes são importantes para qualquer profissional dessa área.
Saiba quais cursos te tornarão um programador
Você sabe o que faz um programador? Para se tornar um — e estar preparado para os desafios do mercado de tecnologia —, é importante escolher um ou mais cursos que não apenas ensinem as linguagens de programação, mas ofereçam uma compreensão dos princípios da computação, sistemas e desenvolvimento de software.
Existem vários cursos disponíveis, cada um com seu próprio foco e especialização, que podem levar você ao sucesso nesta carreira em constante evolução.
Desde cursos que oferecem uma base teórica sólida em computação e algoritmos, até aqueles mais focados no desenvolvimento prático de sistemas e aplicações, a escolha certa depende dos seus interesses específicos e objetivos de carreira.
Por isso, exploraremos algumas dessas opções para entender o que faz um programador e, claro, como cada uma delas pode moldar seu caminho para se tornar o melhor programador.
Análise e Desenvolvimento de Sistemas
Este curso é ideal para quem busca uma formação prática e voltada para o mercado de trabalho. Mas, por quê? Ele ensina desde os fundamentos da programação até o desenvolvimento de sistemas mais complexos e maiores, passando por linguagens de programação diversas, banco de dados, análise de sistemas e gestão de projetos.
A ênfase é dada na resolução de problemas reais do cotidiano empresarial, preparando o aluno para criar soluções inovadoras e eficientes — que podem ser aplicadas no mercado de trabalho.
Ciência da Computação
Pode-se dizer que esse é um dos cursos mais tradicionais na área de TI – e ele vai além do simples ensino de programação. Este curso oferece uma base em algoritmos, estruturas de dados, teoria da computação, inteligência artificial e sistemas operacionais.
Ele é ideal para aqueles que desejam não apenas aprender a programar, mas também entender os princípios teóricos que sustentam a computação, o que é essencial para inovação e pesquisa na área.
Engenharia de Computação
Este curso une a engenharia eletrônica com a ciência da computação. Ele oferece conhecimentos sobre hardware e software, incluindo o design e a integração de sistemas computacionais e eletrônicos.
Além da programação, os alunos também aprendem sobre circuitos eletrônicos, processamento de sinais, comunicações digitais e robótica, preparando-os para inúmeras carreiras na indústria tecnológica.
Engenharia de Software
Como o próprio nome já diz, focado no desenvolvimento de softwares de alta qualidade, este curso ensina os alunos a projetar, desenvolver, testar e manter sistemas de software.
A engenharia de software é, basicamente, sobre aplicar os princípios da engenharia no processo de criação de software, garantindo que os produtos finais sejam confiáveis e eficientes.
Este curso é ideal para quem deseja se especializar em criar soluções de software complexas e em larga escala.
Sistemas de Informação
Este curso é ideal para aqueles que estão interessados em como as tecnologias da informação são utilizadas para atender às necessidades das organizações.
Nele, você aprenderá mais sobre banco de dados, redes de computadores, segurança da informação e desenvolvimento de sistemas, com foco em como essas tecnologias podem ser aplicadas para resolver problemas reais — que, por sua vez, está em constante evolução.
Programação de Computadores
Este curso é focado em ensinar a arte e a ciência da programação. Ele cobre uma variedade de linguagens de programação e paradigmas, desde o desenvolvimento web até a programação de aplicativos móveis e jogos.
É ideal para quem deseja adquirir habilidades práticas rápidas em programação — para entrar no mercado de trabalho ou para trabalhar em projetos pessoais.
Programação de Sistemas
Este curso especializa-se no desenvolvimento de sistemas operacionais, softwares e aplicativos de alto desempenho.
Ele ensina os alunos sobre a programação em baixo nível, gerenciamento de memória, concorrência e otimização de desempenho. É perfeito para aqueles que desejam entender e trabalhar na camada mais fundamental da tecnologia de software.
Conheça alguns tipos de programadores
Agora que você já conhece os cursos que te tornarão um programador, falaremos sobre o que faz um programador.
No mundo da programação, a diversidade de papéis e especializações reflete a complexidade e a evolução constante da tecnologia.
Cada tipo de programador possui um conjunto específico de habilidades e conhecimentos, adaptados para atender às demandas das diferentes áreas do desenvolvimento de software — os quais são muitas.
Vamos explorar alguns dos tipos mais comuns de programadores: Back-End, Full Stack, Front-End e Mobile — para entender como suas funções específicas contribuem para o desenvolvimento e a manutenção de sistemas e aplicativos que usamos diariamente.
Programador back-end
O Programador Back-End é o arquiteto por trás das funcionalidades que operam nos bastidores de um site ou aplicativo.
Mas, como isso funciona? Este profissional é responsável por gerenciar a lógica de servidores, bancos de dados e aplicações, garantindo que todos os componentes interajam em equilíbrio — e da melhor maneira.
Eles trabalham com linguagens como Java, Python, Ruby e frameworks específicos para criar e manter a estrutura que suporta as aplicações.
Resolver problemas e garantir a segurança das aplicações são apenas algumas das habilidades essenciais de Programadores Back-End que garantem o funcionamento correto de sistemas online.
Programador full stack
Você já sabe o que faz um programador Full Stack? Combina habilidades de front-end e back-end, trabalhando em todos os aspectos do desenvolvimento web, desde a interface do usuário até o banco de dados e a lógica do servidor (ou seja, tudo).
Com um grande conhecimento em diversas linguagens de programação, eles podem construir um aplicativo ou site do zero, lidando com cada passo de forma objetiva e prática. Essa versatilidade transforma os programadores Full Stack em profissionais valiosos em equipes de desenvolvimento.
Programador front-end
Especializado na parte visual e interativa de sites e aplicativos, o Programador Front-End é responsável por tudo que os usuários vêem e interagem diretamente.
Eles utilizam linguagens como HTML, CSS e JavaScript para criar layouts, interfaces e elementos interativos.
Além das habilidades técnicas, esses programadores geralmente também possuem um conhecimento — mesmo que básico — em design, garantindo que os produtos digitais sejam não apenas funcionais, mas também esteticamente agradáveis e fáceis de usar.
Afinal, será que um site em perfeito funcionamento com um design mal feito continua sendo “perfeito”?
Na programação, um bom design garante que o software seja intuitivo para os usuários e fácil de adaptar ou expandir pelos desenvolvedores.
Ele também desempenha um papel crítico na otimização do desempenho, na segurança e na facilitação de testes eficazes — e muito mais. Bom, e, afinal, o que faz um programador?
A resposta é… tudo: programa, entende de design, analisa sistemas, gerencia bancos de dados, colabora com equipes, trabalha por conta própria e precisa estar sempre atualizado com as tendências tecnológicas.
Programador mobile
Em 2023, no Brasil, mais de 180 milhões de pessoas estão usando a internet — representando uma taxa de quase 85% da população total.
Exatamente por dados como esses, o Programador Mobile tornou-se um profissional essencial no desenvolvimento de aplicativos para dispositivos móveis.
Eles se especializam em plataformas como Android e iOS, utilizando linguagens e ferramentas como Swift, Kotlin e React Native.
Além das habilidades de programação, estes profissionais devem entender as diretrizes e melhores práticas de cada plataforma, garantindo que os aplicativos ofereçam uma experiência de usuário otimizada e se integrem perfeitamente com diversos dispositivos móveis.
Agora que você já sabe o que faz um programador, acesse o site do Mercado Online Digital para conferir os melhores plugins e temas WordPress licenciados sob a Licença GPL — e mais textos como esse em nosso blog.
O que faz um programador – Dúvidas relacionadas
Como essa profissão não existe há muito tempo, é comum que muitas dúvidas relacionadas o que faz um programador possam surgir. Por isso, aqui vamos responder as principais delas!
Mas não se esqueça que nossa aba de comentários está sempre aberta para você perguntar e, assim, para nós te ajudarmos!
Tem idade para começar a programar?
Não! Não existe idade certa para começar a programar. Seja você um jovem que se interessa pelo assunto e aprende muito por conta própria, ou uma pessoa mais velha que está pensando em passar pela transição de carreiras. Afirmamos: vale a pena!
Após saber que quer ser um cientista da computação, basta ter o ensino médio completo, para que possa cursar a graduação, receber seu diploma e começar a trabalhar na área dos seus sonhos!
Qual é o melhor curso de programação?
A escolha pelo melhor curso de programação, passa inicialmente pela escolha da instituição que irá ministrar o curso. A oferta de cursos na área de TI é imensa e você precisa ser criterioso para não comprar gato por lebre. Pesquise sobre a credibilidade da instituição e converse com ex-alunos. Um bom programador precisa ter muito conhecimento prático, avalie de perto o programa prático da instituição. Entre os melhores cursos de programação podemos destacar:
Metodologias de programação ;
Introdução à ciência da computação;
Desenvolvendo aplicativos para iphone;
Programação avançada;
Sistemas digitais: das portas lógicas ao processado
Um programador faz somente sites?
A resposta é não. Na era tecnológica atual, por trás de TUDO há um programador envolvido. Isso quer dizer que a programação está presente em sites, mas também nos aplicativos que utilizamos, nos assistentes virtuais, como Alexa, nos jogos, no cinema e muito mais.
E nem precisamos falar só o que envolve a internet. O programador atua fora dela também. Como em cidades inteligentes que precisam integrar a população com os serviços públicos, como na mobilidade urbana e a iluminação pública. Isso é programação.
Para saber mais, vale muito a pena conhecer mais sobre a Internet das Coisas (IoT).
Qual área de TI paga melhor?
A questão de valores é super relativa, afinal a área do TI abrange diversas camadas da sociedade e varia de empresa para empresa e de cliente para cliente.
Há profissionais autônomos que possuem sua própria cartela de clientes que podem muitas vezes ganhar bem mais que um programador que trabalha com desenvolvimento de inteligência artificial, por exemplo.
E isso, é uma característica muito boa dessa área. Existem muitas oportunidades por aí e quase todas pagam super bem. Abaixo, você confere uma média salarial de profissões mais promissoras no Brasil;
Desenvolvimento de Sistemas: R$3.108,00
Analista de Dados: R$3.300,00
Business Intelligence: R$3.800,90
Experiência do Usuário (UX): R$4.000,95
Segurança da informação: R$3.789,00
Gestão de projetos: R$6.290,00
Engenheiro de Softwares: R$6.303,00
Vale lembrar que os valores acima são em início de carreira (nível Júnior — menos de 2 anos de atuação). Os salários têm diferenças enormes para profissionais com mais anos de carreira (Sênior — mínimo de 5 anos de atuação).
A faculdade de programação é difícil?
Em si, os cursos de graduação na área da programação não são nenhum bicho de sete cabeças. Como qualquer curso, o estudante que praticar todos os dias e buscar mais fontes de conhecimento, não terá grandes dificuldades durante a formação.
Mas é preciso lembrar que este é um curso considerado de exatas. Se você possui obstáculos quanto à raciocínio lógico e matemática, é possível que tenha dificuldade em alguns semestres. Mas a grade curricular como um todo, não é tão complexa.
No fim, a prática leva à perfeição.
Quanto custa um serviço de programação?
Como dito anteriormente, a programação está presente em todos os cenários econômicos do mundo. A atuação desse serviço está em diferentes áreas da indústria. Por isso mesmo, é preciso saber o que levar em consideração na hora de cobrar por um serviço de programação, veja:
Prazos: em quanto tempo o serviço deve ser entregue;
Demanda do serviço: o que deve ser feito, o grau de complexidade, a mão de obra;
Sua experiência: quanto tempo você tem de atuação no mercado.
Em média, serviços simples na área de programação gira em torno de R$3.000,00, quando o profissional trabalha durante um mês, 8 horas por dia. Isso sem contar com a ajuda de um ajudante.
Conclusão
A tecnologia de informação é realmente um mercado incrível, onde bons profissionais podem obter ganhos reais e realmente significativos. Porém, é preciso muito estudo e dedicação, pois se trata de um setor em pleno desenvolvimento com linguagens que se aperfeiçoam a todo tempo.
Se você gostou deste artigo aproveite para compartilhar em suas redes sociais ou deixe comentários com sugestões de temas que gostaria de ver aqui em nosso blog.
Você sabe o que é overflow? Chegou a hora de descobrir o que é e o porquê ocorre.
Quem nunca teve que lidar com a falta de espaço para dados que atire a primeira pedra. Sabemos que a vida do programador não é nada fácil, ainda mais quando tem que se lidar com a falta de espaço.
É aí que entra o termo overflow, utilizado para se referir a uma situação em que a capacidade de uma variável ou estrutura de dados é excedida, resultando em comportamento inesperado e erros graves.
Estamos falando de sistemas críticos até aplicativos simples, falamos de um problema que pode ser desde pequenas falhas até grandes vulnerabilidades de segurança.
No nosso artigo de hoje, vamos analisar o conceito de overflow, seus tipos, mecanismos de detecção e respostas, e como evitá-los, garantindo a segurança e eficiência no desenvolvimento de software.
Entenda o que é Overflow?
Para começar você precisa entender o que é Overflow. Ele é um termo técnico amplamente utilizado no contexto da programação e desenvolvimento de software.
Podemos imaginar uma situação em que uma operação ou um processo excede os limites estabelecidos para a capacidade de armazenamento ou processamento, diante dessa situação, entendemos que ela pode ocorrer em diversas áreas, desde o armazenamento de dados em variáveis até a alocação de memória em sistemas mais complexos.
Assim, overflow pode resultar em erros inesperados, perda de dados e falhas de segurança, tornando-se uma preocupação constante para programadores e engenheiros de software.
Como funciona
Já que ficou claro o conceito de overflow, falaremos agora como ele funciona. Sendo bastante simples, o funcionamento se dá quando um valor que está sendo manipulado, calculado ou armazenado ultrapassa a capacidade máxima definida para a sua representação ou armazenamento, ocorre o overflow.
Por exemplo, em um sistema que usa um byte (8 bits) para armazenar números inteiros, o maior valor positivo que pode ser representado é 127. Se um cálculo resultar em 128, isso excederá o limite, levando a um overflow, onde o valor se “enrola” de volta para o limite mínimo, neste caso, −128.
Mecanismo de detecção
Existem diversos mecanismos de detecção de overflow, sua implementação dependerá do contexto do problema. Em linguagens de programação, é comum ter mecanismos internos ou bibliotecas que monitoram operações matemáticas ou manipulação de dados para detectar quando um overflow pode ocorrer.
Ferramentas de análise de código e compiladores modernos frequentemente incluem recursos para alertar os desenvolvedores sobre possíveis riscos de overflow durante o processo de compilação ou execução do código.
Resposta ao Overflow
Mas é preciso uma resposta, por isso ao detectar um overflow os sistemas e programas devem ser configurados para responder adequadamente. Isso pode significar incluir/lançar exceções, parar a execução do programa, fazer log de eventos ou executar outras ações que previnam danos maiores.
Em linguagens como C e C++, os programadores precisam ser especialmente cuidadosos, pois o gerenciamento de memória e detecção de erros como o overflow é mais manual e propenso a erros.
Diferentes tipos de Overflow
Podemos encontrar vários tipos de overflow que ocorrem em diferentes contextos de programação e desenvolvimento de software. Alguns dos mais comuns incluem o buffer overflow, integer overflow e stack overflow.
Cada um possui características e implicações específicas, e entender como eles funcionam é fundamental para o desenvolvimento de sistemas robustos e seguros, vamos entender a seguir um pouco melhor cada um deles.
Buffer
Para começar falaremos do Buffer overflow, que acontece quando um programa, ao escrever dados em um buffer (uma área de armazenamento temporário), excede o limite de armazenamento desse buffer.
Isso pode corromper dados adjacentes, levar a falhas de sistema ou até permitir que atacantes executem códigos que afetarão seu sistema. Esse tipo de overflow é frequentemente explorado em ataques de segurança cibernética, e mitigá-lo é uma prioridade para desenvolvedores e administradores de sistemas.
Integer
Outro tipo é o Integer overflow, que ocorre quando uma operação aritmética resulta em um valor que está fora dos limites que podem ser representados pelo tipo de dados usado para armazenar o resultado.
Por exemplo, somar dois números inteiros grandes em um sistema de 32 bits que exceda o limite superior do que pode ser armazenado pode levar a um comportamento inesperado e erros no programa.
Stack h3
Por último, falaremos do Stack overflow acontece quando o espaço alocado para a pilha de chamadas de um programa é excedido. Isso geralmente é resultado de uma recursão muito profunda ou de alocações de memória excessivas na pilha.
O stack overflow pode causar falhas de programa e é um erro comum em muitas linguagens de programação, incluindo aquelas que não possuem um mecanismo de detecção automática.
Saiba como ocorre o Overflow
Mas como realmente ocorre o overflow? A resposta é: quando as suposições sobre os limites de capacidade de um sistema são violadas. Isso pode ser resultado de erros de lógica, falta de verificações adequadas ou manipulação incorreta de dados.
Por exemplo, ao trabalhar com números inteiros, é crucial garantir que as operações não excedam os limites máximos ou mínimos suportados pela representação de dados.
Práticas de codificação inadequadas, como a falta de verificação de limites ao copiar dados para buffers, podem aumentar significativamente o risco de overflow. O uso de funções de biblioteca inseguras ou desatualizadas também pode introduzir vulnerabilidades de overflow nos sistemas.
Conheça os exemplos práticos de Overflow
Falando de mundo real, temos muitos exemplos práticos de overflow, um exemplo clássico é o famoso Y2K Bug, que foi um problema de overflow em que sistemas de software armazenavam datas usando apenas dois dígitos para o ano, o que causou problemas ao mudar do ano 1999 para 2000.
Outro exemplo é o incidente da Patriot Missile no Golfo Pérsico em 1991, onde um erro de overflow de ponto flutuante no sistema de controle do míssil resultou na falha de interceptação de um míssil inimigo, levando infelizmente a perda de vidas de muitas pessoas.
Se pensarmos em termos de segurança, o buffer overflow é frequentemente explorado por invasores para executar código arbitrário em sistemas vulneráveis. Um ataque bem-sucedido pode permitir que o invasor obtenha controle total sobre um sistema afetado.
Impactos do overflow
Já citamos aqui que o overflow pode gerar diversos problemas em sistemas de software, afetando desde pequenas funções até estruturas críticas.
Quando ocorre, o impacto pode ser sentido em vários aspectos do sistema, resultando em uma série de complicações que comprometem a integridade, funcionalidade e segurança da aplicação. A seguir vamos detalhar um pouco mais sobre esse aspecto.
Corrupção de dados
Podemos dizer que a corrupção de dados é um dos principais resultados do overflow. Quando os dados excedem a capacidade de armazenamento de uma variável, os valores podem ser sobrescritos em áreas de memória não destinadas a eles.
Podendo corromper informações importantes, fazendo com que elas fiquem inacessíveis ou imprecisas. Esse problema pode afetar diretamente a integridade dos dados e comprometer o funcionamento correto de sistemas críticos, como bancos de dados e sistemas financeiros.
Falhas no sistema
O overflow também pode levar a falhas no sistema. Em muitos casos, quando uma variável ou estrutura de dados excede sua capacidade, o programa pode parar de funcionar corretamente ou até mesmo encerrar abruptamente.
Essas falhas podem ocorrer de forma intermitente ou constante, dependendo da severidade do overflow, e podem resultar em travamentos inesperados, perda de dados e até necessidade de reinicialização completa do sistema.
Vulnerabilidade de segurança
E temos também outra consequência importante do overflow, que é a criação de vulnerabilidades de segurança. O ataque mais comum relacionado a isso é o buffer overflow (já falamos um pouco dele aqui), no qual invasores exploram o transbordamento de dados para injetar código com má intenção no sistema.
Ao comprometer a memória além de seu limite, o invasor pode executar comandos arbitrários, obter controle do sistema e acessar dados confidenciais. Isso torna o overflow uma porta de entrada para ataques virtuais graves.
Dicas práticas para evitar o overflow
Para evitar os problemas causados pelo overflow, é fundamental adotar boas práticas no desenvolvimento de software. Essas práticas ajudam a reduzir os riscos de transbordamento de dados e a garantir que o código seja mais seguro e eficiente, vamos dar uma olhada nelas a seguir?
Validar os valores de entrada
Primeiramente, a validação de entrada é uma das estratégias mais simples e eficazes para prevenir o overflow. Antes de processar qualquer dado, é importante garantir que ele esteja dentro dos limites aceitáveis para o tipo de variável ou estrutura utilizada.
Essa prática impede que valores inválidos ou excessivos sejam processados, minimizando o risco de exceder a capacidade de armazenamento.
Usar dados adequados
Outra dica importante é utilizar o tipo de dado correto para cada operação. Em muitas situações, o overflow ocorre porque a variável escolhida não tem capacidade suficiente para armazenar os valores que está lidando.
Por exemplo, usar um tipo de dado de 8 bits para armazenar grandes números inteiros pode resultar em overflow. Portanto, ao planejar o código, é fundamental escolher variáveis que suportem o volume de dados esperado.
Realizar verificações de limite
As verificações de limite são outra técnica fundamental para evitar o overflow. Ao implementar limites explícitos no código, você pode garantir que os dados nunca ultrapassem os valores máximos permitidos por uma variável ou estrutura.
Isso pode ser feito tanto para variáveis individuais quanto para buffers e arrays, onde o controle de tamanho é especialmente importante.
Prevenir erros de lógica no código
Muitos casos de overflow podem ser atribuídos a erros de lógica no código. Esses erros ocorrem quando o programador não antecipa cenários nos quais os dados podem exceder os limites.
Se você revisar o código com atenção, utilizar ferramentas de análise estática e seguir boas práticas de programação pode minimizar a ocorrência de erros lógicos que podem resultar em overflow.
Saiba ainda como a CPU calcula o overflow
A detecção de overflow pela CPU é um aspecto técnico importante. A maioria dos processadores modernos possuem mecanismos embutidos para identificar quando ocorre um overflow durante operações aritméticas.
Eles utilizam flags específicas no processador, como a flag de overflow, que é ativada sempre que o resultado de uma operação excede o limite do tipo de dado. Ao identificar essa condição, a CPU pode interromper o processamento ou gerar uma exceção, alertando o desenvolvedor sobre o problema.
Essas técnicas de detecção automática são úteis para evitar que o overflow passe despercebido durante o desenvolvimento e a execução de programas, mas é essencial que o desenvolvedor também tome as precauções necessárias para evitar que o problema ocorra em primeiro lugar.
Confira as ferramentas para gerenciar Overflow
Controlar o Overflow durante o desenvolvimento exige o uso de ferramentas específicas que ajudam a identificar e corrigir esse tipo de falha. Cada uma atua em etapas diferentes do processo e contribui para reduzir riscos em tempo de execução.
As ferramentas de análise estática examinam o código antes da execução, detectando possíveis erros de lógica, manipulação indevida de memória e uso incorreto de variáveis. Já as ferramentas de análise dinâmica verificam o comportamento do programa em tempo real, apontando falhas que só aparecem durante a execução. Os depuradores, por sua vez, permitem acompanhar o passo a passo do sistema, facilitando a identificação da origem exata do erro.
Além dessas, também existem bibliotecas de segurança que ajudam a evitar o Overflow com recursos específicos de proteção de memória e verificação de limites. Vamos entender um pouco mais sobre cada uma delas!
Ferramentas de análise estática
Essas ferramentas analisam o código-fonte sem executá-lo. Elas procuram padrões perigosos, variáveis mal utilizadas, manipulação de memória que pode dar errado. E tudo isso acontece antes do sistema rodar, o que é uma enorme vantagem.
SonarQube, Cppcheck, Coverity e Clang Static Analyzer são alguns nomes que valem ser considerados. Elas examinam cada linha em busca de possíveis erros que levem ao Overflow, como acessos fora dos limites de arrays, aritmética perigosa ou uso descuidado de ponteiros.
O uso de análise estática no fluxo de desenvolvimento, especialmente integrado ao CI/CD, permite que você tenha alertas precoces sobre pontos vulneráveis do código. Isso significa que você pode corrigir antes mesmo de chegar na fase de testes.
Ferramentas de análise dinâmica
Enquanto a análise estática examina o código parado, a análise dinâmica entra em ação enquanto ele está rodando. Ela observa a execução em tempo real e identifica qualquer comportamento anormal que possa indicar Overflow.
Valgrind é um dos exemplos mais conhecidos. Ele consegue apontar o uso de memória não inicializada, acessos fora de limites e muito mais. Outra opção interessante é o AddressSanitizer, que já vem embutido em compiladores como GCC e Clang.
Essas ferramentas mostram onde e como o problema acontece, permitindo um diagnóstico mais preciso. Elas são especialmente úteis quando o erro não é detectado com facilidade, já que analisam o programa no momento exato em que tudo acontece.
Ferramentas de depuração
Quem já passou horas atrás de um bug sabe como um bom depurador faz diferença. Quando o erro está escondido em uma lógica complexa ou acontece de forma intermitente, o uso de ferramentas como GDB ou Visual Studio Debugger facilita muito a vida.
Esses depuradores permitem acompanhar a execução linha por linha, verificar os valores das variáveis e até visualizar o que acontece na pilha de chamadas. Quando se trata de Overflow, isso é fundamental. Você pode observar em tempo real se um ponteiro ultrapassou o que devia, se uma variável passou do limite ou se houve acesso indevido a regiões de memória.
Além disso, com o suporte de logs e mensagens de erro bem pensadas, o processo de depuração se torna muito mais ágil e assertivo.
Bibliotecas de segurança
Evitar o Overflow não precisa depender apenas de boas intenções. Existem bibliotecas que foram desenvolvidas justamente para isso, oferecendo camadas extras de segurança e controle sobre o uso da memória e variáveis sensíveis.
A SafeInt, por exemplo, é excelente para manipular inteiros com segurança, prevenindo estouros durante operações matemáticas. Outra opção é o uso de bibliotecas como LibSafe e StackGuard, que protegem regiões da memória contra acessos indevidos ou maliciosos.
Quem opta por linguagens mais modernas, como Rust, encontra ainda mais tranquilidade. Essa linguagem, por exemplo, já foi criada com foco em segurança de memória, tornando praticamente impossível o uso incorreto de ponteiros ou o surgimento de Overflow por erro de lógica simples.
Se o projeto permite, vale muito considerar soluções que já carregam essa proteção embutida.
Veja quais são as boas práticas no uso de Overflow
Ferramentas são essenciais, mas o comportamento da equipe de desenvolvimento tem um papel decisivo na prevenção do Overflow. Pequenos hábitos fazem muita diferença no longo prazo. E acredite: boas práticas podem evitar horas de dor de cabeça depois.
Seguir padrões de codificação
Ter um padrão de codificação bem definido e compartilhado por toda a equipe ajuda a manter a consistência e a legibilidade do código. Isso não é só organização. É prevenção real.
Funções conhecidas por não checar limites, como gets ou strcpy, devem ser evitadas ou substituídas por versões mais seguras, como fgets ou strncpy. Da mesma forma, é importante ter clareza na manipulação de ponteiros e arrays, documentar limites e validar entradas sempre que possível.
Quando todos seguem o mesmo padrão, os erros se tornam mais visíveis e o risco de Overflow diminui drasticamente.
Revisar código
Code review é um momento precioso para a saúde de qualquer projeto. Não é só sobre encontrar erros, mas sobre reforçar boas práticas e manter a qualidade do código em alta.
Ferramentas como GitHub, GitLab e Bitbucket já oferecem suporte para revisões em pull requests. O ideal é que qualquer modificação passe por ao menos uma revisão, principalmente em áreas críticas do sistema. Essa troca de olhares traz mais segurança e ainda ajuda na evolução técnica do time.
Muitos estouros de memória poderiam ter sido evitados com uma boa revisão. Às vezes, é um detalhe que passa despercebido pelo autor, mas salta aos olhos de quem está com a cabeça fresca.
Usar ferramentas de segurança
Integrar segurança ao pipeline de desenvolvimento é uma decisão estratégica. Quando ferramentas de análise estática e dinâmica fazem parte do CI/CD, fica mais fácil manter um padrão de qualidade em cada entrega.
Com isso, o risco de introduzir falhas de Overflow em produção diminui significativamente. O ideal é configurar alertas e acompanhar métricas como cobertura de testes e frequência de falhas.
Essa automação cria uma cultura de segurança e agilidade. Você não depende apenas da disciplina manual da equipe. O próprio sistema te ajuda a manter tudo nos trilhos.
Conclusão
Como acompanhamos ao longo do texto, overflow é uma questão crítica em programação que pode ter impactos significativos no funcionamento e segurança de sistemas de software.
Desde erros matemáticos simples até falhas de sistema catastróficas, o erro pode manifestar-se de várias formas. É essencial que os desenvolvedores entendam os diferentes tipos de overflow, como detectá-los e como implementar medidas eficazes para preveni-los.
Conheça a Programação Orientada a Objetos (POO), que faz parte dos paradigmas de programação e surgiu como uma alternativa às características da programação estruturada – mas, na verdade, é muito mais do que apenas “uma alternativa” a algo.
A Programação Orientada a Objetos (POO) é muito mais do que um mero paradigma de programação; é uma filosofia que se infiltra na estrutura de cada software. Mas, como isso acontece? O que são os “objetos” dessa tal programação? E, afinal, para que serve a POO?
Imagine que você está construindo um quebra-cabeças e, ao invés de peças aleatórias, cada peça é uma miniatura perfeitamente formada de uma parte do mundo real – um carro, uma casa, uma árvore… Essa é a essência da Programação Orientada a Objetos (POO): uma maneira de programar que imita o mundo real.
Na POO, cada “peça” do seu software é um objeto; um pacote autocontido de dados e os respectivos métodos responsáveis por manipular esses dados. Além de tornar o programa mais compreensível e parecido com a forma como vemos percebemos o mundo real, a POO ainda facilita o manuseio de projetos complexos, viabilizando a concentração (por parte dos desenvolvedores) em um objeto de cada vez.
Os pilares da Programação Orientada a Objetos incluem quatro conceitos-chave principais: encapsulamento, herança, abstração e polimorfismo.
Encapsulamento: Protege os dados dentro de um objeto, evitando acesso externo não autorizado, por exemplo;
Herança: É justamente através dela que um objeto herda as propriedades e métodos de outro, promovendo a reutilização de código e a criação de hierarquias de objetos;
Abstração: Facilita a modelagem de objetos complexos ao expor apenas os detalhes relevantes e escondendo as implementações específicas;
Polimorfismo: Refere-se à capacidade de um método de assumir diferentes formas de comportamento (dependendo, claro, do contexto em que é utilizado), o que proporciona o tratamento de objetos de diferentes classes como objetos de uma classe comum. Através do polimorfismo, o efeito de dois objetos de classes diferentes, por exemplo, têm o mesmo efeito;
Comparada a paradigmas mais tradicionais, como a programação procedural, a POO oferece uma perspectiva e prática de programação mais organizada e escalável para o desenvolvimento de software.
Enquanto a programação procedural se concentra em funções e na sequência de execução de tarefas, a POO agrupa tarefas (métodos) com os dados que manipulam (objetos), resultando em um código mais intuitivo e adaptável.
Ao contrário da programação funcional, que foca na imutabilidade e no uso de funções puras, a POO desperta uma maior flexibilidade através de estados mutáveis e interações entre objetos, adaptando-se perfeitamente a ambientes de software que exigem uma representação dinâmica do estado.
Benefícios e aplicabilidade da POO
A Programação Orientada a Objetos (POO) oferece uma série de vantagens responsáveis por justificar seu reconhecimento e adoção em diversos setores da indústria de software.
Aqui vão os principais benefícios da POO:
Reutilização de código
A POO promove a reutilização de código de formas que outros paradigmas não conseguem replicar ou igualar. Através do mecanismo de herança, por exemplo, novas classes podem ser criadas sobre as existentes, estendendo e customizando funcionalidades sem que um código existente precise ser reescrito.
Modularidade
Cada objeto em POO é uma entidade autônoma com suas próprias propriedades e comportamentos.
É exatamente através dessa modularidade que os desenvolvedores constroem sistemas que agem como uma série de módulos independentes e que o sistema (como um todo) é melhor compreendido, já que cada módulo passa a ser desenvolvido e testado de forma independente antes de ser integrado ao sistema maior.
Colaboração eficiente
A modularidade da POO também se traduz em uma colaboração mais eficiente entre os desenvolvedores. Em grandes equipes, diferentes grupos podem trabalhar em módulos separados sem interferir no trabalho uns dos outros em nenhum momento.
Em ambientes de desenvolvimento ágil, onde várias iterações e revisões são comuns, essa eficiência na colaboração faz toda a diferença.
Facilidade de manutenção e escalabilidade
A manutenção do software fica mais simples com a POO – graças ao seu design encapsulado. Alterações em um objeto específico não costumam afetar outros objetos, desde que a interface do objeto permaneça sempre consistente. Isso torna o sistema mais estável e menos propenso a bugs durante a manutenção.
Conceitos essenciais da POO
Agora, nada melhor do que conhecer os conceitos essenciais da POO para ter uma ideia de como ela funciona, de verdade, na prática:
Classes e objetos
As classes atuam como moldes para a criação de objetos, e cada classe define os atributos (propriedades) e comportamentos (métodos) que os objetos criados a partir dela possuirão.
Um objeto é uma instância de uma classe, com dados reais que seguem a estrutura previamente definida por ela (a classe). Esse relacionamento é a principal “lei” da POO, e é por meio dele que os softwares são modelados com estruturas próximas às do mundo real.
Definição, propriedades e métodos
A definição de uma classe em POO especifica quais dados (propriedades) um objeto pode conter e que ações (métodos) ele pode executar.
As propriedades nada mais são do que características do objeto, como tamanho, cor ou estado, enquanto os métodos são funções que definem as ações que os objetos podem realizar, como calcular um valor, modificar uma propriedade ou interagir com outros objetos.
Encapsulamento, herança e polimorfismo
Encapsulamento: Refere-se à prática de esconder os detalhes internos do funcionamento de um objeto e expor apenas os componentes necessários para a interação externa (o que protege os dados do objeto de acessos e modificações indevidas);
Herança: Como você já sabe, é a capacidade que uma nova classe tem de derivar de uma classe já existente. A classe derivada herda características da classe base, podendo ganhar novas funcionalidades ou modificar as funcionalidades presentes nessa mesma classe base;
Polimorfismo: É por meio deleque métodos com o mesmo nome se comportam de maneira diferente em diferentes classes. Isso é fundamental para a reutilização de código e para a implementação de interfaces que podem interagir de formas distintas conforme o contexto em que são chamadas.
Abstração e encapsulamento
A abstração é o ato de esconder a complexidade específica de uma implementação, expondo apenas uma interface necessária para a interação.
Já o encapsulamento, que, por sua vez, é um aspecto da abstração, envolve a ocultação dos detalhes internos do objeto para protegê-lo e evitar usos inadequados. Juntos, eles facilitam a manutenção e a expansão do software.
Separação da interface da implementação
Este princípio orienta os desenvolvedores a separar “o que” um objeto faz de “como” ele faz, através da definição deinterfaces. As interfaces definem os métodos pelos quais um objeto expõe ao mundo exterior, enquanto a implementação detalha como esses métodos são executados internamente.
Isso provoca mudanças na implementação de um objeto, que são feitas com um impacto mínimo sobre o código que faz uso desse objeto, promovendo flexibilidade e facilitando atualizações e manutenção.
Confira alguns exemplos de POO
Como vimos a POO é um paradigma amplamente utilizado no desenvolvimento de software. Sua popularidade deve ser de forma eficiente como organização do código, promovendo maior legibilidade, facilidade de manutenção e reutilização de componentes.
Esse paradigma é baseado em conceitos fundamentais, como encapsulamento, herança e polimorfismo, que tornam o desenvolvimento mais estruturado e escalável. A seguir, conheceremos exemplos de POO em diferentes linguagens de programação, destacando como cada uma implementa esses princípios.
Exemplo em Python
Python é conhecido por sua simplicidade e legibilidade, o que o torna uma das linguagens favoritas para aprender POO. Sua sintaxe intuitiva permite que até mesmo iniciantes compreendam facilmente conceitos como classes, métodos e atributos.
O Python também oferece suporte robusto a herança e polimorfismo, facilitando o desenvolvimento de sistemas modulares e reutilizáveis. Além disso, a comunidade ativa e a vasta documentação fazem do Python uma excelente escolha para implementar POO em projetos de qualquer escala.
Exemplo em Java
Java é uma linguagem voltada a objetos por design, amplamente utilizada no desenvolvimento de aplicativos empresariais, aplicações web e sistemas móveis. Sua estrutura fortemente tipada exige que os programadores sigam padrões rígidos ao implementar conceitos de POO, ou que garantam consistência e segurança no código.
Os modificadores de acesso, como private e public, ajudam a encapsular dados, enquanto os métodos sobrescritos e a herança promovem a extensibilidade, e claro, não devemos esquecer que Java também é conhecido por sua robustez e capacidade de criar sistemas confiáveis e escaláveis, sendo ideal para projetos corporativos.
Exemplo em C#
C# é uma linguagem moderna, desenvolvida pela Microsoft, que combina características de linguagens como Java e C++. Ela é altamente versátil e amplamente utilizada em aplicativos Windows, jogos com Unity e desenvolvimento web com ASP.NET. OC# oferece uma abordagem simplificada para POO, com uma sintaxe clara que favorece a criação de classes bem definidas e propriedades para encapsular dados.
Além disso, sua integração com o .NET Framework e suporte a recursos avançados, como interfaces e eventos, tornam o C# uma ferramenta poderosa para projetos baseados em POO.
Exemplo em C++
C++ é uma linguagem de programação poderosa e versátil, amplamente utilizada em sistemas que exigem alto desempenho, como jogos, sistemas embarcados e softwares gráficos. Apesar de sua complexidade, o C++ oferece suporte avançado para POO, permitindo o uso de herança múltipla e polimorfismo.
Sua flexibilidade permite que os desenvolvedores combinem paradigmas estruturados e orientados a objetos, aproveitando o melhor de ambos os mundos. No entanto, o C++ exige maior atenção ao gerenciamento de memória, tornando-o mais adequado para desenvolvedores experientes.
Código limpo e sólido para o uso de POO
A programação orientada a objetos vai além de simplesmente criar classes e objetos. Para escrever códigos eficientes, claros e simples de manter, é fundamental adotar boas práticas que promovam a organização e reduzam a complexidade.
Códigos limpos não apenas melhoram a experiência do desenvolvedor, mas também facilitam a colaboração em equipe e a evolução do sistema ao longo do tempo, e agora vamos saber como aplicá-lo.
KISS (Keep It Simple, Stupid)
O princípio KISS reforça a importância da simplicidade no desenvolvimento de software. Em POO, isso significa evitar a criação de métodos ou classes desnecessariamente complicadas. Projetar aulas com responsabilidades bem definidas é uma maneira eficaz de manter o código limpo e funcional.
A simplicidade não implica falta de sofisticação, mas sim a habilidade de resolver problemas da forma mais direta e eficiente possível. Códigos mais simples são menos propensos a erros e mais simples de limpar.
DRY (Don’t Repeat Yourself)
A repetição do código é um dos principais inimigos da manutenção em projetos de software. O princípio DRY incentiva a eliminação da duplicação por meio da criação de métodos reutilizáveis, herança e composição.
No POO, os programadores podem estruturar o código de forma que funcionalidades sejam centralizadas, reduzindo o risco de inconsistências e tornando alterações futuras mais simples de implementação. Essa abordagem não só economizou tempo, mas também melhorou a organização e a clareza do código.
Programação estruturada vs programação orientada a objetos
A escolha do paradigma de programação depende do tipo de projeto e de suas necessidades específicas. Enquanto a programação estruturada é eficiente para tarefas menores e mais simples, o POO se destaca na criação de sistemas complexos e em constante evolução. Descubra agora as características e diferenças entre as duas.
Características da programação estruturada
A programação estruturada é um paradigma baseado em funções e controle de fluxo. O código é dividido em partes menores, chamadas funções, que executam tarefas específicas. Esse modelo é direto e fácil de aprender, tornando-o ideal para projetos menores ou para resolver problemas pontuais.
No entanto, a falta de encapsulamento e a dependência de variáveis globais podem dificultar a manutenção de sistemas maiores, especialmente em equipes de desenvolvimento.
Características da programação orientada a objetos
A POO organiza o código em torno de objetos, que representam entidades do mundo real. Cada objeto é uma instância de uma classe, contendo atributos e métodos que encapsulam dados e comportamentos relacionados.
Esse paradigma facilita a reutilização de código por meio de herança e composição, enquanto o polimorfismo permite que métodos sejam adaptados para diferentes contextos. A POO é ideal para projetos de grande escala, onde a organização e a modularidade são essenciais.
Comparação geral
Embora ambos os paradigmas tenham suas vantagens, um POO é mais adequado para projetos complexos e colaborativos, onde a reutilização e a manutenção do código são prioridades. A programação estruturada, por outro lado, é mais simples e direta, sendo uma boa escolha para tarefas menores ou projetos de curto prazo.
Ao compreender as diferenças e as aplicações de cada paradigma, os desenvolvedores podem fazer escolhas mais informadas e adequadas às necessidades de seus projetos. Seja estruturada ou orientada a objetos, a abordagem certa sempre dependerá do contexto e do objetivo final do software.
Programação procedurais vs. orientadas por objetos
Para começar, é essencial entender a raiz dessa diferença. A programação procedural segue uma lógica linear, baseada em procedimentos, funções e uma sequência de comandos. Ela resolve problemas dividindo o programa em pequenas tarefas, que são executadas uma após a outra.
Já a POO trabalha de uma forma diferente. Ela organiza o código em “objetos”, que são como miniaturas do mundo real dentro do sistema. Cada objeto tem suas características (atributos) e seus comportamentos (métodos). Isso traz uma visão muito mais próxima de como interagimos com o mundo.
Para ficar bem claro: enquanto na programação procedural você descreve passo a passo como uma ação deve acontecer, na POO você cria entidades que sabem o que fazer sozinhas.
Estrutura e Organização
Quando se fala em organização, a POO dá um verdadeiro show. Ela permite que o código seja dividido em classes, que são como moldes para criar objetos.
Por exemplo, pense em um sistema bancário. Você pode ter uma classe chamada Conta Bancária, que possui atributos como saldo, número da conta e nome do titular, além de métodos como sacar, depositar e transferir. Cada cliente do banco é um objeto que segue esse molde.
Essa estrutura não só deixa o código mais organizado, como também facilita o entendimento de quem trabalha no projeto, reduz erros e torna tudo muito mais escalável.
Abordagem
O grande diferencial da POO está na sua abordagem. Ela enxerga o software como um conjunto de objetos que interagem entre si. Isso é muito diferente da programação procedural, que foca apenas em funções isoladas e dados soltos.
Essa abordagem orientada a objetos ajuda o desenvolvedor a pensar de forma mais intuitiva. Afinal, tudo no mundo real funciona assim: objetos com características e comportamentos. Carros, usuários, produtos, contas bancárias… tudo isso pode ser representado em POO.
Reutilização de Código
Quem já precisou refazer o mesmo código várias vezes sabe o quanto isso é cansativo e ineficiente. E é aí que a POO brilha.
Através de conceitos como herança, polimorfismo e encapsulamento, ela permite que pedaços de código sejam reaproveitados em diferentes partes do projeto.
Por exemplo, imagine que você criou uma classe chamada Veículo com métodos como acelerar e frear. Depois, pode criar classes como Carro, Moto e Caminhão, que herdam tudo que já foi definido em Veículo, sem precisar reescrever. Isso reduz drasticamente o retrabalho e torna o desenvolvimento muito mais ágil e eficiente.
Facilidade de Manutenção
Quando o projeto cresce, a manutenção vira um desafio enorme, principalmente em códigos feitos no modelo procedural. Cada alteração pode gerar efeitos colaterais em várias partes do sistema, muitas vezes difíceis de rastrear.
A POO resolve isso de forma elegante. Como os objetos são independentes e encapsulam seus dados e comportamentos, é muito mais fácil alterar uma funcionalidade sem quebrar o resto do sistema.
Exemplo de Linguagens
Praticamente todas as linguagens modernas oferecem suporte à POO. Algumas delas nasceram orientadas a objetos, outras incorporaram esse paradigma com o tempo.
Essas linguagens não só suportam POO, como também são base para milhões de sistemas no mundo todo.
Quando usar cada uma?
Nem sempre a POO é a melhor escolha, e saber quando aplicar cada paradigma é sinal de maturidade na programação.
A programação procedural é extremamente eficiente para scripts simples, automações rápidas e tarefas bem definidas, onde não há necessidade de grande escalabilidade ou manutenção constante.
Por outro lado, a POO é indispensável quando se fala em desenvolvimento de sistemas robustos, aplicativos que vão crescer ao longo do tempo ou projetos que precisam de manutenção constante. Em cenários como esses, ela oferece uma base muito mais sólida e confiável.
Descubra como e quando surgiu a POO
A história da POO começa lá na década de 1960, dentro do laboratório da Norsk Data Elektronikk, na Noruega. O cientista da computação Ole-Johan Dahl e seu colega Kristen Nygaard desenvolveram uma linguagem chamada Simula, considerada a primeira linguagem orientada a objetos da história.
O objetivo inicial era modelar sistemas complexos, como simulações de tráfego e processos industriais. A partir desse conceito, a ideia se espalhou e, nas décadas seguintes, deu origem a linguagens como Smalltalk, C++ e, mais recentemente, Java, que popularizou de vez a POO no mundo inteiro.
Confira exemplos práticos de onde a POO é aplicada
A POO (Programação Orientada a Objetos) não é só um conceito bonito dos livros de programação. Ela está no centro de praticamente tudo que envolve tecnologia no nosso dia a dia. Desde quando você acessa seu banco pelo celular, faz uma compra online ou simplesmente pede um lanche no aplicativo, tudo isso funciona graças à POO.
A grande mágica da POO é transformar coisas do mundo real em modelos digitais, criando objetos que possuem características (atributos) e ações (métodos). É assim que sistemas se tornam mais inteligentes, seguros, organizados e fáceis de evoluir.
Sistemas bancários
Se você já se perguntou como os bancos conseguem processar milhões de transações todos os dias, com segurança e precisão, a resposta tem muito a ver com a POO.
Em um sistema bancário, cada elemento é representado como um objeto. Por exemplo:
Cliente: possui nome, CPF, endereço, renda e pode realizar ações como abrir conta, solicitar empréstimo, consultar saldo.
Conta Bancária: tem número, agência, saldo, tipo de conta, e métodos como sacar, depositar e transferir.
Transações: cada movimentação é um objeto, que guarda dados como valor, data, origem e destino.
Isso não é só sobre organização. É sobre escalabilidade e segurança. Segundo dados do Banco Central, em 2023, o sistema financeiro brasileiro processou quase 42 bilhões de transações só via Pix. Imagine se isso fosse feito com programação procedural? Seria muito mais complexo de manter, menos seguro e extremamente suscetível a erros.
A POO permite que cada elemento do sistema se comporte de forma independente, mas interaja de forma organizada. E o mais importante: ela facilita atualizações. Por exemplo, quando surgem novas regras de segurança ou novos produtos, os programadores não precisam reescrever tudo, eles apenas atualizam ou criam novos objetos.
Jogos
No desenvolvimento de jogos, a POO é praticamente uma regra de ouro. Isso porque o conceito de objetos faz total sentido dentro do universo de qualquer game.
Pensa em um jogo como FIFA ou Gran Turismo. Cada carro, jogador, estádio ou torcida é um objeto:
Um carro tem atributos como cor, modelo, velocidade máxima, e comportamentos como acelerar, frear, derrapar.
Um personagem em um RPG tem vida, força, armadura, inventário, e pode atacar, defender, usar magia ou itens.
A vantagem da POO é criar uma hierarquia organizada. Por exemplo, se o desenvolvedor quer criar vários tipos de inimigos, ele cria uma classe “Inimigo”, que tem comportamentos básicos como “atacar” ou “receber dano”. Depois, ele herda essa classe para criar inimigos específicos: dragão, zumbi, robô… cada um com suas características únicas, mas compartilhando comportamentos comuns.
Plataformas de e-commerce
Quando você navega por plataformas como Amazon, Mercado Livre, Shopee ou Magazine Luiza, na prática, está interagindo com dezenas de objetos criados pela POO.
Produto: nome, preço, descrição, estoque, fotos e comportamentos como ser adicionado ao carrinho ou ser avaliado.
Usuário: possui CPF, endereço, histórico de compras, carrinho, favoritos.
Pedido: é um objeto que agrupa produtos, endereço de entrega, método de pagamento e status (em preparação, enviado, entregue, cancelado).
A escalabilidade dessas plataformas depende diretamente da organização proporcionada pela POO. Imagina um evento como a Black Friday, onde essas plataformas lidam com milhões de acessos e pedidos simultâneos. Só é possível garantir que tudo funcione bem graças à modularização dos sistemas.
Aplicativos móveis
Pega qualquer app do seu celular: iFood, Instagram, Uber, Spotify. Todos eles são construídos com base na POO.
Vamos usar o iFood como exemplo:
O pedido é um objeto. Ele tem atributos como ID, status (em preparo, a caminho, entregue), valor total, itens.
O restaurante é outro objeto, com nome, cardápio, horário de funcionamento, tempo estimado de entrega.
O entregador também é um objeto, com localização, nome, veículo, e status (disponível, em entrega).
Graças à POO, esses aplicativos conseguem gerenciar milhões de objetos simultaneamente. E mais: a manutenção se torna mais simples. Se o iFood decide adicionar uma nova funcionalidade, como permitir que você agende pedidos para daqui a dois dias, os desenvolvedores só precisam atualizar o objeto “Pedido” para incluir um novo atributo, como “Data de entrega programada”. Sem a necessidade de reescrever tudo do zero.
Conclusão
Agora, não lhe restam mais dúvidas: os objetos da Programação Orientada a Objetos referem-se a algo genérico e que podem representar qualquer elemento concreto (que se pode tocar). A POO é um paradigma de desenvolvimento que, por meio de diferentes conceitos, cria um software mais modular, flexível e fácil de manter.
A Programação Orientada a Objetos (POO) é uma maneira de escrever e organizar um software de maneira com que as partes que o compõem se pareçam mais com objetos do mundo real, onde cada “objeto” (no software) representa uma coisa específica, como um documento, uma imagem ou um usuário.
Engitech – Tema WordPress para Empresas de TI, Startups e Serviços Digitais
O Engitech é um tema WordPress moderno e versátil, ideal para empresas de tecnologia, startups, agências de software, desenvolvimento de aplicativos e consultorias em TI. Desenvolvido com design limpo e estrutura profissional, ele oferece tudo que você precisa para criar um site corporativo de alto impacto.
Funcionalidades e Benefícios Principais
Design Profissional e Moderno Com visual elegante e layouts cuidadosamente pensados, o Engitech transmite credibilidade e inovação — ideal para empresas que querem causar uma primeira impressão sólida.
Construtor Visual Elementor Incluso Crie páginas com liberdade total utilizando o Elementor, o construtor mais popular e fácil de usar do WordPress. Arraste, solte e personalize tudo sem precisar de código.
Demonstrações Prontas para Importar Várias opções de demos completas e seções pré-construídas que podem ser importadas com um clique. Ideal para quem quer agilidade na criação do site.
Totalmente Responsivo e Retina Ready O tema se adapta perfeitamente a todos os dispositivos, garantindo uma experiência fluida em smartphones, tablets e desktops.
Compatível com WooCommerce Permite adicionar uma loja online ou vender serviços digitais diretamente no site, com integração nativa com o WooCommerce.
Layouts de Portfólio e Cases de Sucesso Exiba seus projetos, aplicações, soluções e histórias de sucesso com layouts visuais otimizados para conversão e credibilidade.
Blog Corporativo Integrado Publique artigos, atualizações e insights do setor com uma estrutura de blog que reforça sua autoridade e melhora o SEO do site.
Otimizado para Performance e SEO Código limpo, carregamento rápido e estrutura pensada para melhorar sua posição nos motores de busca desde o início.
Elementos Visuais de Alta Qualidade Ícones modernos, animações suaves, seções com parallax, contadores, depoimentos e chamadas para ação já prontos para uso.
Painel de Opções Completo Configure cores, tipografias, cabeçalho, rodapé, espaçamentos e muito mais diretamente do painel de administração do WordPress.
Por Que Escolher o Engitech?
Ideal para empresas que atuam com TI, desenvolvimento web, SaaS, consultoria digital e soluções tecnológicas
Pronto para uso profissional com foco em credibilidade, performance e conversão
Ótimo equilíbrio entre design moderno e usabilidade
Permite construir sites corporativos robustos sem depender de programadores
O Engitech é a escolha perfeita para negócios de tecnologia que buscam um site institucional moderno, funcional e com visual profissional. Seja para conquistar novos clientes, apresentar soluções ou reforçar autoridade no setor, esse tema entrega tudo que sua empresa precisa.
Por que usar um ORM? Aprenda agora a facilitar a comunicação entre SQL e linguagens de programação orientadas a objetos.
A cada dia surgem novas ferramentas digitais que diminuem o tempo de trabalho em várias áreas do mercado. E na programação não é diferente, onde existem diversos recursos que otimizam o workflow sem precisar passar horas em um código básico.
Pensando nisso, falaremos a seguir sobre o ORM (Object Relational Mapper) ou, como o nome sugere, um Mapeamento Relacional de Objetos. Sua função é criar uma ligação entre banco de dados e aplicações, poupando horas de escrita de código. Veja como funciona:
Saiba o que é ORM
O ORM é um recurso utilizado durante a fase de desenvolvimento de software para mapear objetos presentes em um banco de dados relacional (SQL). No passado, esse código era escrito manualmente (e alguns ainda o fazem), porém, o ORM automatiza esse processo.
Sua maior característica é a interação do código relacionado com sistemas de bancos de dados. O programador tem a liberdade de não precisar fazer consultas SQL e nem se preocupar com a forma como os objetos são armazenados, em um processo de abstração.
Entenda para que serve o ORM
Para além do fato da otimização de um processo detalhado, o ORM garante algumas vantagens em cadeia quando utilizado. O recurso promove uma programação mais segura e mais profissional, viabilizando parâmetros como:
Ter o código limpo
Um código escrito possui uma série de elementos e caracteres que, se excluídos, não terão o menor impacto, como o uso de espaços, por exemplo. Com o ORM ocorre um processo parecido, onde o objeto não está mais inserido em uma SQL.
O que ocorre é que o ORM divide essa programação em dois lados, a lógica de negócios e a lógica do acesso ao banco de dados. Assim, temos uma leitura mais simplificada, subdividida e, portanto, mais fácil de entender.
Evita erros típicos
Como consequência da otimização, o ORM evita erros humanos já que toda sua estrutura já está pronta para ser utilizada. É uma ferramenta que não necessariamente precisa ser projetada. Basta utilizá-lo para dar um boost no seu processo.
Assim, não somente erros de digitação são evitados, como também o uso de caracteres que não fazem sentido para a aplicação. Isso melhora não somente a organização, mas também deixa a programação mais leve.
Grau alto de portabilidade
Para quem ainda não sabe, a maior desvantagem de um banco de dados SQL é que existe um limite muito pequeno entre as combinações de linguagens de programação. Muitas vezes um banco de dados não consegue interpretar aplicações com linguagens diferentes.
ORM é recomendado por promover a interação entre os dois itens em diferentes Sistemas de Gerenciamento de Banco de Dados (SGBDs). Ou seja, se o código não for escrito diretamente em SQL, poderá ser migrado para diferentes bancos de dados.
Saiba como funciona a estrutura do ORM
A interação entre objetos e um banco de dados só pode ser concretizada a partir de vários conceitos aplicados na ORM. Tais conceitos são divididos em camadas que organizam a projeção entre um objeto e um SQL.
Veja abaixo quais são estas camadas:
Camada de Abstração do Banco de Dados
Na primeira camada de um ORM, ocorre a divisão do que pertence ao objeto e o que foi traduzido para o banco de dados relacional. De forma abstrata, é possível manusear os dados sem se aprofundar na complexidade do SQL, isso é feito pelo ORM.
E assim, essa consulta passa a ser analisada em níveis de complexidade e necessidade diferentes. O ORM vai agir conforme as especificidades de suas demais camadas, que continuaremos nos tópicos a seguir.
Camada de Mapeamento Objeto-Relacional
A segunda fase do processo de estruturação do ORM é o mapeamento entre o objeto e o banco de dados relacional. É aqui que inicia a “ponte” entre estes dois fatores. Na premissa, o que é feito em um, vai surtir efeito no outro.
De forma simplificada, essa interação é permitida pela denominação de classes para cada objeto onde ocorre uma “tradução” direta para o banco de dados relacional. Essas classificações são definidas quase sempre em propriedade, valor, chave, mapeamento e relação.
Camada de Gerenciamento de Transações
O manuseio dos bancos de dados através do ORM é outro ponto muito importante. Se baseando na ACID (atomicidade, consistência, isolamento e durabilidade), permite iniciar, commitar e desfazer transações com facilidade, sem comprometer a SQL.
Esse mecanismo (que é uma API), controla a execução das operações feitas dentro do banco de dados. Leva em consideração a consistência dos dados, o que promove um ambiente mais seguro para a integridade da informação.
Camada de Consulta
A camada de consulta é, por tabela, o motivo principal da popularidade do ORM. Isso quer dizer que o recurso permite trabalhar os dados como se fossem a abstração do objeto, sendo assim, não é preciso escrever um SQL.
O benefício disso é um workflow mais ágil, evitando que o desenvolvedor/programador passe horas escrevendo um SQL correspondente ao banco de dados utilizado. Vale destacar que a consulta se torna mais prática, filtrando os dados de maneira útil.
Camada de Caching
Para melhorar a consulta de dados, ORM possui um cache de direcionamento próprio. Mas, nesse caso, os dados que mais se repetem entram nesse parâmetro. O objetivo é melhorar a responsividade da aplicação, a fim de melhorar o tempo de resposta.
Além disso, o caching do ORM evita que termos estejam se repetindo ao longo da aplicação. Assim conseguimos um banco de dados mais enxuto e apenas com as informações que importam.
Conheça as vantagens de usar o ORM
Adotar um ORM em projetos de desenvolvimento de software traz uma série de benefícios. Será que você conhece alguns deles?
Ao agilizar e simplificar a interação entre a aplicação e o banco de dados, o ORM não só economiza tempo, como também aumenta a qualidade do código. Esta ferramenta, que diminui a complexidade das operações de banco de dados, permite que os desenvolvedores se concentrem mais na lógica de negócios — e melhorando a eficiência do desenvolvimento.
A utilização de um ORM contribui (e muito) para a segurança da aplicação. Ao automatizar a geração de consultas SQL, reduz-se a vulnerabilidade a ataques de injeção SQL – um dos problemas mais comuns em aplicações web.
Além disso, ao simplificar os detalhes do banco de dados, o ORM impede a exposição inadvertida de estruturas de dados sensíveis, elevando, desta maneira, a segurança dos dados.
Ao lidar com dados, erros manuais podem comprometer a segurança. O ORM, por sua vez, minimiza esses riscos ao gerenciar automaticamente as operações de banco de dados. Isso significa que os padrões de segurança são consistentemente aplicados, sem depender da atenção constante dos desenvolvedores (o que é essencial em ambientes de programação).
Menos escrita
Está aí um dos maiores benefícios do ORM: a redução significativa da quantidade de código necessário para interagir com o banco de dados, que, além de economizar tempo, também torna o código mais limpo e fácil de manter.
Ao eliminar a necessidade de escrever consultas SQL (que geralmente são repetitivas e complexas), o ORM permite que os desenvolvedores se concentrem em aspectos mais críticos da aplicação. Essa eficiência nos leva a um ciclo de desenvolvimento mais rápido e, claro, a um produto final mais confiável.
Interação com bancos de dados
O ORM simplifica a interação entre a aplicação e o banco de dados. Mas, como?
Isso significa que os desenvolvedores podem realizar operações de banco de dados sem necessariamente terem um grande conhecimento de SQL – tornando o processo mais inclusivo e eficiente.
Com ORM, a aplicação se torna mais versátil e compatível com diferentes bancos de dados. Isso ocorre porque o ORM pode se adaptar a diferentes SGBDs, o que é útil em ambientes onde a migração de dados (ou a interoperabilidade entre diferentes sistemas) é necessária.
Diminui o custo
Ao aumentar a eficiência e reduzir o tempo necessário para o desenvolvimento, o ORM também diminui significativamente os custos operacionais. Menos tempo de desenvolvimento significa menor uso de recursos, o que, por sua vez, se traduz em economia de custos para a empresa.
Acelera o tempo
A implementação do ORM acelera o ciclo de desenvolvimento de software – ou seja: acelera o tempo. Ao automatizar tarefas repetitivas e frequentes e reduzir a complexidade do código, o tempo de entrega do projeto é significativamente reduzido.
Em um ambiente de desenvolvimento ágil, a capacidade de responder rapidamente a mudanças é essencial. O ORM proporciona essa agilidade, e permite que os desenvolvedores façam ajustes de forma rápida sem a necessidade de reescrever longas seções de código relacionadas ao banco de dados.
No universo do desenvolvimento de software, as ferramentas de ORM (Object Relational Mapping) desempenham um papel essencial em diferentes linguagens de programação. Cada linguagem possui seus próprios frameworks de ORM, otimizados para trabalhar com suas peculiaridades e paradigmas.
Essas ferramentas facilitam a interação entre o código do programa e o banco de dados relacional, ajudando a manter o código mais limpo, seguro e eficiente. Vamos explorar algumas das ferramentas ORM mais populares para Java, .NET, Python e PHP.
ORM para Java
Hibernate: No mundo Java, o Hibernate é uma das ferramentas ORM mais conhecidas e utilizadas. Este framework se destaca pela sua capacidade de lidar com operações de banco de dados complexas de maneira eficiente.
O Hibernate, além de simplificar o mapeamento entre entidades Java e tabelas de banco de dados, também fornece alguns recursos avançados, como lazy loading e caching, responsáveis por melhorar o desempenho.
JPA (Java Persistence API): O JPA nada mais é do que uma especificação para a persistência de dados em Java, usada como base para vários frameworks ORM – incluindo o Hibernate. Ela define um conjunto de conceitos e padrões que facilitam o mapeamento objeto-relacional, tornando o desenvolvimento mais intuitivo (e menos propenso a erros).
ORM para .NET
Entity Framework: O Entity Framework é a solução ORM mais popular na plataforma .NET. Este framework, mantido pela Microsoft, permite que os desenvolvedores trabalhem com dados usando objetos .NET, sem necessariamente precisar se preocupar com as consultas SQL.
Ele também suporta diversas funcionalidades de banco de dados, como migrações, consultas LINQ e lazy loading.
Dapper: Conhecido por sua alta performance, o Dapper é outra ferramenta ORM muito utilizada na comunidade .NET. Ele é extremamente rápido e eficaz para cenários onde o desempenho é crítico.
ORM para Python
Django ORM: No ecossistema Python, o Django ORM é uma ferramenta importantíssima, principalmente para quem trabalha com o framework web Django. Este ORM se destaca por sua integração com o Django, que facilita o desenvolvimento rápido de aplicações web de forma clara e eficiente.
SQLAlchemy: o SQLAlchemy é outro ORM popular em Python, conhecido por sua flexibilidade. Ele oferece aos desenvolvedores a capacidade de trabalhar em um alto nível de abstração, mas também permite um controle detalhado nas operações de banco de dados quando necessário.
ORM para PHP
Doctrine: No mundo do PHP, o Doctrine é um dos melhores ORMs. Mas, por quê? É simples: ele não apenas gerência o mapeamento objeto-relacional, mas também oferece ferramentas adicionais para a geração de esquemas de banco de dados, migrações e muito mais. Eloquent ORM: Integrado ao Laravel (um framework PHP), o Eloquent ORM oferece uma abordagem simples para o ORM. Intuitivo e fornecendo recursos como relações de modelos e mutadores, o Eloquent transforma o trabalho com banco de dados PHP em uma tarefa muito mais simples.
Entenda por que usar ORM
Com o ORM, você consegue mapear tabelas do banco de dados para objetos no código de forma super prática. Esqueça aquelas longas linhas de SQL para tarefas simples, o ORM resolve isso de maneira elegante.
Outro ponto forte de usar ORM é a organização. Quando seu projeto cresce, fica fácil perder o controle dos acessos ao banco. Usando ORM, as operações ficam padronizadas e centralizadas, o que deixa tudo mais limpo e fácil de entender, principalmente em equipes grandes.
Se o seu projeto é cheio de recursos orientados a objetos, como herança e polimorfismo, pode apostar que o ORM vai ser um grande aliado. Ele conversa muito bem com esse tipo de estrutura, o que facilita o desenvolvimento e manutenção do sistema.
E tem mais: se você busca um código mais limpo, organizado e sem aquele tanto de SQL espalhado pra todo lado, o ORM pode fazer toda diferença. De quebra, você ainda economiza tempo, principalmente no desenvolvimento inicial.
Descubra as desvantagens de se usar ferramentas ORM
Apesar de todos esses pontos positivos, usar ORM também tem seu lado B e é importante falar sobre isso sem rodeios.
A primeira coisa que muita gente sente na pele é que aprender a usar ferramentas ORM pode ser demorado. Não é só instalar e sair usando. Existem boas práticas, padrões de configuração, técnicas específicas… E ignorar essa curva de aprendizado pode gerar dor de cabeça lá na frente.
Outra questão é o desempenho. Se seu projeto precisa lidar com consultas muito complexas, aquelas cheias de junções, filtros e regras de negócio, talvez o ORM não seja seu melhor amigo. Por mais que ele facilite muita coisa, no fim das contas, o SQL escrito à mão costuma ser mais rápido e otimizado nesses casos.
Aliás, falando em velocidade, não tem como negar: as ferramentas ORM geralmente são mais lentas que trabalhar diretamente com SQL. É uma consequência natural do processo de abstração que elas criam. Para sistemas pequenos e médios, isso pode passar despercebido. Mas, em projetos de grande porte, essa diferença pode impactar bastante o desempenho.
Aprender a usar ferramentas ORM pode ser demorado
Muita gente fica em dúvida se vale a pena investir tempo estudando ORM, principalmente porque no começo parece que o SQL direto resolveria tudo mais rápido. Só que a verdade é que, dominando uma boa ferramenta ORM, você ganha um superpoder para acelerar o desenvolvimento de muitos tipos de projetos.
Claro, tem o desafio inicial, as configurações podem ser meio chatas e é fácil se perder no meio das abstrações. Mas, com paciência e prática, o ORM vira uma ferramenta que ajuda a manter o projeto saudável e sustentável a longo prazo.
Outro detalhe importante: aprender ORM também ajuda a entender melhor como os bancos de dados funcionam nos bastidores. E ter esse conhecimento é algo que diferencia muito o nível técnico de um desenvolvedor.
Não terá um desempenho melhor com consultas muito complexas
Esse é um dos principais pontos de atenção. Quando o assunto são consultas extremamente complexas, daquelas cheias de junções, subconsultas, filtros pesados, confiar somente no ORM pode se tornar um problema.
O ORM foi feito para simplificar, não para otimizar ao máximo as consultas. Em muitos casos, ele gera SQLs gigantescos, com vários “joins” desnecessários, o que pode prejudicar o desempenho do banco de dados. Quando a aplicação exige velocidade e precisão, principalmente em consultas específicas, o bom e velho SQL manual ainda dá show.
Por isso, vale muito a pena analisar a complexidade das operações que seu projeto exige. Em alguns momentos, usar o ORM para o básico e consultas diretas para o que é crítico pode ser a melhor solução.
As ferramentas de ORMs são mais lentas do que usar SQL
Não tem jeito: abstrair informações tem um preço, e no caso do ORM, esse preço geralmente é a velocidade.
A camada extra que o ORM cria para traduzir objetos em consultas SQL gera uma pequena sobrecarga. Para projetos pequenos e médios, isso dificilmente é perceptível. Mas em aplicações que lidam com milhares ou milhões de registros, essa diferença de performance pode se tornar significativa.
Outro detalhe: ferramentas ORM costumam carregar mais dados do que o necessário em certas operações. Por exemplo, um simples acesso a um cliente pode puxar junto todos os pedidos dele, mesmo que você não precise dessa informação naquele momento. Esse comportamento, conhecido como eager loading, precisa ser muito bem controlado para evitar problemas de performance.
Confira se vale a pena usar um ORM no seu projeto
Antes de adotar um ORM, é essencial fazer uma análise honesta sobre as necessidades do seu projeto. Colocar no papel os prós e contras pode evitar muita dor de cabeça lá na frente.
Se o foco for produtividade, rapidez no lançamento e facilidade de manutenção, o uso de ORM se justifica bastante. Já se o principal critério for desempenho máximo em consultas específicas e controle absoluto sobre o banco, talvez seja melhor investir mais tempo escrevendo SQL à mão.
Também é importante considerar a expertise da equipe. Se ninguém está familiarizado com a ferramenta ORM escolhida, o tempo de aprendizado pode pesar no cronograma.
Se seu projeto for de grande porte
Projetos de grande porte costumam exigir decisões muito mais criteriosas. Quando o sistema envolve muitos usuários simultâneos, operações em tempo real e volumes gigantes de dados, o ORM precisa ser usado com moderação.
O ideal, nesses casos, é adotar uma abordagem híbrida: usar o ORM para as operações comuns e o SQL puro para os pontos críticos que exigem alta performance. Essa combinação garante o melhor dos dois mundos, produtividade sem abrir mão de performance.
Inclusive, existem ORMs que permitem essa flexibilidade de forma muito tranquila, dando liberdade ao desenvolvedor para usar consultas nativas quando necessário.
Se você quer economizar tempo
Se a palavra de ordem no seu projeto é agilidade, o ORM vai ser seu melhor amigo. Automatizando a maior parte das interações com o banco de dados, ele deixa o desenvolvedor livre para focar no que realmente importa: construir funcionalidades.
Com ORM, operações como criação de tabelas, alterações de estrutura e consultas básicas são feitas quase sem esforço. Em projetos onde o tempo de entrega é curto, essa economia de trabalho é essencial para manter o ritmo sem comprometer a qualidade.
Como o ORM já integra práticas recomendadas de segurança, como proteção contra SQL Injection, você ainda economiza tempo que seria gasto implementando essas proteções manualmente.
Se seu projeto utiliza muitos recursos orientados a objetos
Projetos que fazem uso pesado de conceitos como herança, polimorfismo e encapsulamento se beneficiam muito do uso de ORM.
A integração entre o modelo de dados e a estrutura do código fica muito mais natural. Você consegue, por exemplo, criar classes que refletem perfeitamente a estrutura das tabelas e aproveitar ao máximo os benefícios da orientação a objetos, sem precisar fazer malabarismos para sincronizar dados.
Se a arquitetura do seu sistema é toda pensada em cima de objetos, não usar ORM pode fazer você perder muitas das vantagens dessa abordagem.
Se você busca um código mais limpo e fácil de entender
Um dos pontos mais subestimados quando falamos sobre ORM é o impacto que ele tem na organização do projeto.
Com o ORM, seu código fica mais expressivo. Em vez de escrever SQLs gigantes dentro de métodos, você trabalha diretamente com objetos e métodos intuitivos, que descrevem de forma muito mais clara o que está acontecendo.
Essa limpeza faz uma diferença enorme quando outra pessoa da equipe precisa dar manutenção no sistema, ou até mesmo quando você, meses depois, volta para aquele projeto. Entender o que foi feito fica muito mais fácil e seguro.
Conclusão
Um ORM é um sistema integrado ao banco de dados relacional e direcionado a objetos em uma aplicação. Sua maior vantagem é automatizar o processo de consulta, que muitas vezes é feito manualmente, o que pode gerar erros e ser um processo demorado.
Com diversos parâmetros, o ORM cria uma ponte entre o banco de dados e a aplicação. Assim, ocorre um mapeamento que resulta em consultas mais práticas e um manuseio que respeita a atomicidade, consistência, isolamento e durabilidade (ACID) de uma aplicação.
Agora que você entendeu como funciona o ORM, é hora de saber quais outros recursos podem ajudar em seus projetos. Acompanhe a MOD e saiba mais.
Você já se deparou com o temido erro 502 Bad Gateway? Ele surge quando você tenta acessar um site e, ao ser recebido pela página desejada, é saudado por uma mensagem de erro. Hoje você vai descobrir mais sobre.
Imagine que você está navegando pela internet, buscando informações, relaxando em seu site favorito ou até mesmo comprando aquele item desejado. De repente, ao tentar acessar uma página, você é interrompido por uma mensagem de erro.
E não há nenhum erro, mas o temido “502 Bad Gateway” aparece. A frustração é instantânea, mas antes de se desesperar, é bom entender o que está por trás disso.
O erro 502 Bad Gateway ocorre quando um servidor, que atua como uma “ponte” entre o seu computador e o servidor de destino, não consegue obter uma resposta válida do servidor de origem. Parece confuso, mas, na prática, isso significa que algo deu errado durante a comunicação entre os servidores.
Neste texto, vamos falar sobre as principais causas desse erro, como identificar sua origem e, claro, dicas para evitá-lo no futuro. Preparado para desmistificar o 502 Bad Gateway? Vamos lá!
Afinal, o que é o erro 502 Bad Gateway?
Em termos simples, o erro 502 Bad Gateway é um problema de comunicação entre servidores. Isso acontece quando um servidor intermediário, também chamado de gateway ou proxy, tenta acessar outro servidor para obter a resposta desejada, mas, por algum motivo, não consegue se comunicar corretamente.
O servidor intermediário envia um pedido, mas o servidor de destino responde com algo inesperado ou nada. Como resultado, você acaba de receber a mensagem de erro 502.
Esse erro geralmente não é causado por algo em seu dispositivo ou em sua conexão com a internet, mas sim por questões do lado do servidor. Quando você vê essa mensagem, o problema está em algum lugar na “estrada” entre o seu computador e o servidor da página que você está tentando acessar.
Principais causas do erro 502 Bad Gateway
Agora que entendemos o que é o erro 502 Bad Gateway, vamos conhecer as principais causas que podem levar a esse problema. Existem várias razões pelas quais você pode se comparar com esse erro, e é importante estar ciente delas para poder resolvê-las de forma eficiente.
Problemas no servidor de origem
Um dos principais problemas do erro 502 é o servidor de origem, ou seja, o servidor onde o site ou aplicação está hospedado. Se o servidor de origem estiver fora do ar, sobrecarregado ou com problemas internos, ele poderá falhar ao processar a solicitação enviada pelo servidor intermediário. Nesse caso, o gateway não recebe uma resposta válida e, como resultado, exibe o erro 502.
Existem vários problemas internos que podem afetar o servidor de origem, como falhas de software, erros de configuração ou até mesmo falta de recursos (como memória ou processamento). Em muitos casos, os administradores de servidores podem resolver o problema reiniciando o servidor ou ajustando suas configurações.
Configuração de rede ou firewall
Outro fator importante que pode causar o erro 502 Bad Gateway são as configurações de rede ou firewall. Um firewall é uma ferramenta de segurança que filtra o tráfego de entrada e saída de um servidor para proteger contra acessos não autorizados. No entanto, se um firewall estiver mal configurado, ele poderá bloquear a comunicação entre o servidor intermediário e o servidor de origem, resultando no erro 502.
Além disso, configurações incorretas de rede, como problemas de DNS (Domain Name System), podem interferir na capacidade de um servidor de resolução ou nome de domínio de outro servidor. Quando isso acontece, o servidor intermediário não consegue acessar o servidor de origem corretamente e, novamente, exibe o erro 502.
Falhas no CDN (Content Delivery Network)
Os CDNs (Content Delivery Networks) são sistemas distribuídos que ajudam a acelerar o carregamento de sites, armazenando e entregando conteúdo de servidores localizados em diferentes regiões. Embora os CDNs tenham melhor desempenho, eles também podem ser responsáveis por erros do 502 Bad Gateway.
Se um CDN estiver fora de funcionamento, mal configurado ou sobrecarregado, o servidor intermediário poderá tentar acessar o conteúdo armazenado no CDN. Isso resulta em uma falha na comunicação entre os servidores, ocasionando o erro 502.
Sobrecarga de tráfego
A sobrecarga de tráfego é outra causa comum do erro 502 Bad Gateway. Quando um site recebe uma quantidade de tráfego muito superior à sua capacidade de processamento, o servidor de origem pode ficar sobrecarregado e incapaz de responder a todas as entregas feitas pelos usuários.
Quando isso acontece, o servidor intermediário não consegue obter uma resposta do servidor de origem, resultando no erro 502.
Esse tipo de problema geralmente ocorre durante picos de tráfego, como grandes promoções em lojas online, lançamentos de produtos ou quando um site viraliza repentinamente. Para evitar esse tipo de sobrecarga, muitos sites utilizam técnicas de balanceamento de carga e servidores adicionais para distribuir o tráfego de maneira eficiente.
Saiba como identificar a origem do problema
Agora que você já conhece as principais causas do erro 502 Bad Gateway, é hora de aprender como identificar de onde vem o problema. Aqui estão algumas maneiras de descobrir o que está causando o erro e como corrigi-lo:
Verifique o status do servidor : se você tem acesso ao servidor de origem, a primeira coisa a fazer é verificar se ele está funcionando corretamente. Veja se o servidor está ativo, se os recursos como memória e CPU não estão sobrecarregados e se não há falhas de software.
Revise as configurações do firewall : se você tem controle sobre as configurações de rede e firewall, verifique se não há regras que incluam o bloqueio da comunicação entre o servidor intermediário e o servidor de origem. Desative temporariamente o firewall para testar a comunicação entre os servidores.
Consulte o CDN : caso você esteja utilizando um CDN, verifique se ele está funcionando corretamente. Muitas plataformas de CDN possuem painéis de controle onde você pode verificar o status dos servidores e a distribuição de tráfego. Se o CDN estiver com problemas, tente desativá-lo temporariamente para ver se isso resolve o erro.
Análise de logs : os logs de erros do servidor são uma excelente fonte de informações para diagnosticar problemas. Procure mensagens relacionadas ao erro 502 e veja se há alguma indicação de qual servidor ou serviço está causando a falha.
Dicas para evitar o erro 502 Bad Gateway
Embora não seja possível garantir que o erro 502 nunca ocorra, existem algumas práticas que podem ajudar a minimizar as chances de ele acontecer e melhorar a experiência do usuário e separamos elas para você.
Utilize balanceamento de carga : para evitar sobrecarga de tráfego, tente uma implementação de balanceamento de carga. Isso distribui as comunicações entre vários servidores, mantendo a pressão sobre qualquer servidor único e ajudando a manter o site funcionando sem problemas.
Monitore o servidor constantemente : realize monitoramento constante do servidor para detectar problemas antes que eles causem falhas graves. Ferramentas de monitoramento de servidor podem ajudar a identificar problemas como alta utilização de CPU, falta de memória ou falhas de software.
Revise as configurações de rede e firewall : Certifique-se de que suas configurações de rede e firewall estejam corretamente ajustadas e não estejam bloqueando comunicações essenciais entre servidores.
Escolha um bom serviço de hospedagem : se você está lidando com um servidor compartilhado ou uma hospedagem de baixa qualidade, o erro 502 pode ser mais frequente. Optar por uma hospedagem confiável e com boa infraestrutura pode evitar muitos problemas.
Otimize o uso de CDNs : se você estiver usando um CDN, certifique-se de que ele está configurado corretamente e que os servidores de cache estão distribuindo conteúdo de forma eficiente. Escolher um bom serviço de CDN pode ajudar a reduzir a carga nos servidores de origem e melhorar o desempenho do site.
Saiba como resolver o erro 502 Bad Gateway
Ninguém merece estar navegando de boas e de repente se deparar com aquele alerta: 502 Bad Gateway. Dá até uma mini frustração, né? Mas respira fundo, porque esse erro não é o fim do mundo. Ele basicamente significa que, por algum motivo, dois servidores não estão se entendendo direito.
Felizmente, tem várias formas simples de resolver isso, seja você visitante ou dono do site. Vamos descomplicar?
Atualize a página
Sério, às vezes o caminho mais fácil é o mais certeiro. O erro 502 Bad Gateway pode aparecer por uma falha super momentânea, tipo um soluço no servidor. Dar aquele clássico F5 ou clicar em “atualizar” pode ser o suficiente para tudo voltar ao normal.
Se o site tava sobrecarregado ou passou por alguma instabilidade rapidinha, recarregar pode resolver na hora. E, vamos combinar, essa é a tentativa mais fácil e rápida de todas.
Confirme se há um problema no site
Antes de começar a fuçar no seu computador achando que ele virou um bloco de concreto digital, vale conferir se o problema é realmente com você. Uma dica boa é usar sites como Down For Everyone Or Just Me. Ele te mostra se o site está fora do ar só pra você ou pra geral.
Se o erro 502 Bad Gateway aparecer pra todo mundo, pode relaxar, a culpa não é sua. Nesse caso, o site provavelmente está passando por alguma manutenção ou problema no servidor, e tudo o que dá pra fazer é aguardar.
Troque de navegador e limpe o cache
Seu navegador pode estar guardando informações antigas e confusas, tipo aquela gaveta cheia de papéis inúteis. E isso pode atrapalhar o carregamento do site. Tenta abrir o mesmo endereço em outro navegador (como trocar o Chrome pelo Firefox ou o Safari pelo Edge). Se der certo, o problema tava no cache mesmo.
Para garantir que ele não te sabote de novo, limpa os dados armazenados, cookies, cache, histórico. Isso dá uma renovada na navegação e pode mandar o erro 502 pra bem longe.
Reinicie o roteador
Ah, o bom e velho “desliga e liga de novo”! Nunca subestime o poder dessa tática. Às vezes, a conexão entre você e a internet dá uma engasgada e interfere no acesso aos sites. Reiniciar o roteador pode resolver possíveis conflitos de IP ou pequenas falhas na rede. É como dar um reset na sua conexão com o mundo.
E o melhor: geralmente, funciona! Então, se o erro 502 Bad Gateway insistir em aparecer, corre ali, desliga o roteador, espera uns segundinhos e liga de novo. Vai que rola!
Troque o DNS
O DNS funciona como uma lista telefônica da internet, ele traduz o nome do site, em um número que o servidor entende. Mas às vezes, essa tradução dá errado. Trocar o DNS pode ser o pulo do gato para resolver o erro 502 Bad Gateway.
Uma dica legal é usar servidores DNS públicos, como os do Google ou do Cloudflare. Essa mudança é simples, rápida e pode te ajudar a contornar problemas de rede que estão fora do seu controle. Tipo driblar o trânsito usando um caminho alternativo.
Atualize e reinicie o computador
Pode parecer coisa de técnico preguiçoso, mas reiniciar o computador realmente resolve muita coisa. Se algum processo estiver travado, um navegador bugado ou até alguma extensão atrapalhando o carregamento, dar um reboot pode liberar tudo.
E se tiver atualização pendente, melhor ainda, aproveita pra instalar. Deixar o sistema em dia evita que pequenos erros virem grandes dores de cabeça. Inclusive, em muitos casos, o erro 502 Bad Gateway desaparece como mágica depois de um simples reinício.
Afinal, o erro 502 Bad Gateway significa que o site foi invadido?
Essa pergunta aparece direto e com razão. Quando vemos uma mensagem de erro esquisita, é normal pensar no pior. Mas relaxa, na maioria das vezes, o erro 502 Bad Gateway não tem nada a ver com invasões ou hackers. Ele geralmente surge por causa de falhas de comunicação entre servidores, atualizações mal feitas ou sobrecarga.
Claro, não dá pra descartar completamente problemas de segurança, mas invasão é mais exceção do que regra. Se o erro persistir e você for o dono do site, vale dar uma investigada mais profunda.
Descubra se o Erro 502 Bad Gateway é permanente
Tem erro que vai e volta rapidinho, e tem erro que parece querer morar no site. O 502 Bad Gateway, quando aparece esporadicamente, costuma ser temporário. Mas se ele começa a dar as caras com frequência, aí já é sinal de alerta.
Para quem é dono do site, isso pode indicar problemas mais sérios com o servidor, plugins bugados, mal funcionamento de firewall ou até conflitos entre aplicativos instalados. Se estiver rolando direto, não dá pra ignorar.
O ideal é monitorar, testar e corrigir o que for necessário para garantir que tudo funcione direitinho.
Entenda o impacto do erro 502 Bad Gateway no SEO
A gente sabe que SEO é rei quando se trata de visibilidade na internet. E sim, o erro 502 Bad Gateway pode prejudicar muito o desempenho de um site nos motores de busca. Imagina o Google tentando acessar seu site várias vezes e só encontrando erro? Isso sinaliza que o site é instável, e o Google começa a enxergar isso com maus olhos.
O resultado? Queda nas posições do ranking e menos tráfego orgânico. Para quem trabalha com conteúdo, vendas ou serviços online, isso pode significar prejuízo real. Então, além de resolver rápido, é importante garantir que ele não vire figurinha repetida.
Ferramentas de diagnóstico para identificar erro 502 Bad Gateway
Não precisa ser programador ninja pra usar algumas ferramentas que ajudam a entender o que está acontecendo nos bastidores do site. Existem opções bem intuitivas que dão uma luz pra quem quer resolver o erro 502 Bad Gateway sem ficar chutando.
Postman
O Postman é tipo aquele amigo que manda a real. Ele serve para testar requisições e verificar como o servidor está respondendo. É muito usado por quem trabalha com APIs, mas qualquer pessoa com interesse técnico consegue usar.
Ele te mostra se a comunicação entre os sistemas tá fluindo como deveria ou se tem alguma falha no caminho. É uma das formas mais certeiras de identificar se o problema tá mesmo na resposta do servidor.
GTmetrix
O GTmetrix é uma mão na roda pra quem quer analisar a performance geral do site. Apesar de focar em velocidade e otimização, ele também ajuda a detectar travamentos, lentidão e problemas que podem gerar o erro 502 Bad Gateway.
Ele faz um raio-x completo da página e entrega insights super úteis. Dá até pra ver qual parte do carregamento tá emperrando. Com isso, fica bem mais fácil saber onde mexer.
New Relic
Esse aqui é o Sherlock Holmes dos diagnósticos de servidor. O New Relic monitora tudo em tempo real: uso de CPU, banco de dados, tempo de resposta e muito mais. Ele vai fundo mesmo, e se tiver algo estranho rolando, ele mostra. Ideal para quem gerencia sites com bastante tráfego ou estrutura mais complexa.
Com ele, dá pra identificar gargalos, prevenir falhas e manter o erro 502 Bad Gateway bem longe da sua rotina.
Conclusão
O erro 502 Bad Gateway pode ser frustrante tanto para os usuários quanto para os administradores de sites. Felizmente, a compreensão das causas comuns desse erro e a adoção de boas práticas para evitar sua ocorrência podem ajudar bastante.
Monitore constantemente seus servidores, aprimore suas configurações de rede e tente o uso de balanceamento de carga e CDNs de qualidade para manter seu site funcionando de maneira eficiente.
Entenda o que é CRUD e como esse conjunto de operações ajuda na análise inteligente de sistemas de informação.
Na ciência de dados, uma forma de manipular os sistemas é através de etapas processuais que garantem uma visualização clara do que precisa ser feito. O conceito de CRUD é um tipo desses processos, mais especificamente quando voltados para softwares em SQL.
Na leitura de hoje entenderemos o que é CRUD e como esse processo que, embora seja básico na ciência da informação, pode ajudar os desenvolvedores a programar com mais agilidade e organização. Veja.
Saiba o que é CRUD
A sigla em inglês, CRUD significa: Create (Criar), Read (ler), Update (Atualizar) e Delete (Excluir). Como o termo sugere, são uma série de funções para a leitura e manipulação efetiva de análise de bancos de dados.
Embora possa parecer confuso de imediato, essas funções são extremamente básicas e servem para manipular com mais clareza um sistema de dados, tornando a atividade do usuário em uma interface mais simples, objetiva e intuitiva.
Entenda para que serve o CRUD
De modo geral, esse importante conceito da programação estabelece que as operações a seguir tem o principal objetivo de facilitar a gestão de informações. Principalmente em programas SQL (Structured Query Language), ou seja, aqueles baseados em tabelas.
Cada operação do CRUD denomina uma função específica que faz parte de praticamente todo software que lida com tabelas e a própria manipulação de informações.
Durante o desenvolvimento de um programa que se baseia em banco de dados, o programador deverá construir as ferramentas necessárias para que o usuário seja capaz de criar, ler, atualizar e excluir todos os dados que lhe forem autorizados.
Saiba o que é o CRUD backend
O CRUD Backend consiste nas operações fundamentais que funcionam em prol do funcionamento do processamento interno do banco de dados. Ou seja, esse CRUD é uma aplicação que facilita a integração entre as ações dos usuários nos navegadores e o banco de dados do sistema.
Assim, o CRUD Backend permite que você crie registros, leia informações, atualize registros e delete registros que não são mais utilizados na sua navegação. Tudo isso torna o uso da internet mais fácil e rápido, melhorando a qualidade do ambiente digital para o usuário.
Por que criar o CRUD?
O CRUD não somente deve ser criado como também é um pilar principal do desenvolvimento de sistemas SQL. Para o usuário, uma tabela que não pode ser criada, lida, atualizada ou deletada, não possui sua função mais óbvia: a manipulação de dados.
Agora que você já sabe o que é CRUD, entenda por que criar o CRUD é tão fundamental:
Reutilização de código
Um CRUD bem projetado permite a reutilização do mesmo código em diferentes aplicações. A economia de tempo conquistada será um avanço que evitará mais esforço durante processos repetitivos, evitando a necessidade de novo desenvolvimento de códigos
Compartilhamento de conhecimento
A criação do CRUD reforça as noções mais básicas de sistemas de interação interface-usuário. Essa atividade ajuda a compartilhar conhecimentos com a equipe e uma maneira mais assertiva de projetar em uma equipe multidisciplinar.
Demonstração de habilidades
O CRUD é uma das tarefas mais comuns feitas pelos programadores. É essencial mostrar habilidade de desenvolvimento de software quando esse processo requer uma dedicação em tempo integral do seu conhecimento.
Aprendizado contínuo
O desafio de desenvolver o CRUD é uma oportunidade de aprendizado. Com essa tarefa que requer atenção aos mínimos detalhes, você será capaz de aprimorar habilidade de programação, design de banco de dados e a segurança cibernética da interface do usuário.
Aprenda aqui como criar o CRUD
A seguir, entenderemos quais são os processos que levam à criação do CRUD. Não entrarei no intuito do passo a passo do desenvolvimento, afinal, esse processo pode ser feito através das mais variadas linguagens de programação e para diversos propósitos. Sendo assim, veja onde focar para desenvolver um bom CRUD para sua database:
Planejamento: levando em consideração o processo de deploy, estabeleça quais são os requisitos mínimos para o desenvolvimento do CRUD, bem como a tecnologia apurada;
Criação do Banco de Dados: Defina chaves primárias para criar a estrutura do banco de dados, projetando as tabelas com os campos necessários para o armazenamento da informação;
Implementação: Crie as operações CRUD propriamente ditas que permitirão que o usuário crie, leia, atualize e exclua dados de interesse;
Interface do Usuário: a interface está intrinsecamente ligada ao CRUD, o usuário deve ser capaz de realizar operações de CRUD de maneira intuitiva;
Testes: tenha certeza de que as operações de CRUD podem ser realizadas com facilidade e que elas surtam efeito desejado na manipulação de dados;
Segurança: Defina medidas de seguranças que, quando implementadas, protejam o sistema de ataques de injeção de SQL que são muito comuns nestas programações;
Implantação e manutenção: Agora permita que o CRUD esteja livre para o acesso de usuários autorizados e faça um acompanhamento periódico em busca de gargalos.
Lembrando sempre que a implementação completa de um CRUD varia a depender da linguagem de programação abordada. É importante entender os princípios subjacentes de operações CRUD e como adaptá-los às ferramentas utilizadas.
Cuidados importantes na criação do CRUD
A criação do CRUD não é uma tarefa complicada, porém, exige cuidados essenciais. Isso porque essa ação envolve a entrada de dados dos clientes no seu banco de dados, e essas informações devem ser tratadas com zelo e bastante atenção.
Então, os principais cuidados importantes na criação do CRUD:
Nunca deixe de tratar e validar as entradas do usuário;
Lembre-se que nenhum sistema está livre de ataques cibernéticos;
Realize a paginação sempre que buscar uma lista com vários registros;
Busque apenas os dados que o usuário necessite ver;
Diminua, ao máximo, o volume de dados que serão processados e trafegados, para deixar o sistema mais rápido;
Sempre busque abrir a conexão com o banco de dados o mais tarde possível e fechá-la o mais rápido possível, para evitar problemas de conexão e concorrência no banco de dados.
Conheça o significado das operações CRUD
Como você já sabe, CRUD é um acrônimo para as quatro operações básicas realizadas em bancos de dados ou sistemas de armazenamento de informações: Create (Criar), Read (Ler), Update (Atualizar) e Delete (Excluir).
Essas operações formam a base da maioria dos sistemas de gestão de dados, e, com as operações CRUD, os aplicativos passam a interagir entre eles e a gerenciar dados de uma maneira ainda mais eficaz. Mas, por quê?
É simples: a estrutura padronizada e intuitiva das operações CRUD facilita a automatização e a simplificação do processamento de dados.
O entendimento completo dessas operações é fundamental para desenvolvedores de software, analistas de sistemas (e, na realidade, qualquer outro profissional que trabalhe com a tecnologia da informação), uma vez que oferecem a base para criar, consultar, modificar e eliminar dados em um sistema.
Create
A operação de criação refere-se ao processo de adicionar novos registros (ou dados) ao banco de dados. É o primeiro passo no ciclo de vida de dados — e, nesta etapa, os sistemas acumulam informações essenciais para as suas respectivas funções.
Por exemplo, ao criar um novo perfil de usuário em um aplicativo, a operação “Create” é utilizada para adicionar os detalhes do usuário ao banco de dados.
Read
A operação de leitura é utilizada para consultar e recuperar dados do banco de dados. Com essa função, a visualização das informações armazenadas pode ser feita sem modificar o conteúdo já existente.
Seja listando todos os registros disponíveis ou buscando dados específicos por meio de critérios, ou filtros, a operação “Read” é essencial na hora de acessar e exibir informações.
Update
Esta etapa refere-se ao processo de modificar dados já existentes no banco de dados. Essa operação é essencial — justamente porque, como o próprio nome já diz, mantém as informações dos dados atualizadas.
Por exemplo, se um usuário deseja alterar uma senha ou atualizar seu perfil, a operação “Update” seria responsável por aplicar essas mudanças no registro correspondente.
Delete
O objetivo da operação de exclusão é um: remover dados do banco de dados. Essa função é importantíssima na hora de gerenciar o ciclo de vida dos dados — já que, com ela, os sistemas podem eliminar informações desnecessárias ou supérfluas.
Contudo, fica o adendo: a função Delete (Excluir) deve ser usada sempre com muita cautela — já que a exclusão de dados é, na maioria das vezes, irreversível.
Vantagens e desvantagens do conceito CRUD
Vantagens:
O CRUD oferece um conjunto padronizado de operações com foco na interação com bancos de dados — e, por consequência, facilita a compreensão e a implementação por desenvolvedores;
As operações CRUD são intuitivas, e, por isso, tornam o processo de design, desenvolvimento e manutenção de sistemas mais simples e direto;
Facilita a automatização do gerenciamento de dados — da criação a exclusão de registros —+, otimizando processos e reduzindo erros manuais;
Com essas operações, os desenvolvedores podem adaptar e expandir sistemas com mais facilidade (e praticidade), atendendo às novas necessidades de negócios ou mudanças nos requisitos.
Desvantagens:
Para aplicações com requisitos de dados muito complexos, o modelo CRUD pode não ser o suficiente;
A implementação errada e inadequada das operações CRUD pode expor os dados a riscos de segurança (como a injeção de SQL, por exemplo), exigindo atenção especial às práticas de segurança;
Em sistemas com grandes volumes de dados, operações CRUD mal otimizadas podem afetar o desempenho dos respectivos sistemas e dados;
A operação Delete, se mal administrada, pode levar à perda acidental de dados importantes.
Importância do CRUD no desenvolvimento de software
No universo do desenvolvimento de software, as operações CRUD (Create, Read, Update, Delete) são fundamentais. Elas representam as ações básicas que os usuários podem realizar sobre os dados em qualquer sistema, garantindo a capacidade de gerenciar e manipular informações de maneira eficaz.
Sem CRUD, os sistemas seriam estáticos, incapazes de responder às necessidades dinâmicas dos usuários ou aos requisitos de negócios em constante mudança.
Interatividade com o Usuário
A interatividade com o usuário é essencial no desenvolvimento de software: ela influencia diretamente a usabilidade e a satisfação do usuário final — e, se você trabalha com esta área da tecnologia ou ao menos conhece o básico sobre ela, com certeza já sabe como uma boa interatividade com o usuário faz toda a diferença em cada sistema ou projeto.
O CRUD fornece um nível de personalização e controle fundamental para a experiência do usuário. Isso, além de melhorar a satisfação dos usuários, também pode aumentar a retenção e o engajamento.
Operações CRUD fornecem feedback imediato aos usuários após cada ação, reforçando a sensação de interatividade e resposta do sistema. Isso é essencial em sistemas interativos, onde a percepção de imediatismo e eficácia é valorizada.
Manutenção de Dados
A manutenção de dados é um aspecto importantíssimo da gestão de sistemas de informação: ela garante que os dados sejam precisos, confiáveis e estejam disponíveis sempre que necessário.
Com operações de atualização, os dados se mantêm sempre relevantes e precisos — e isso é crucial para a tomada de decisões baseada em dados e, claro, para a integridade e o funcionamento geral do sistema.
Poder excluir dados ociosos ou duplicados ajuda a manter o banco de dados limpo — otimizando, desta maneira, o desempenho e a utilização de recursos.
Flexibilidade
A flexibilidade é um atributo desejável em qualquer sistema de software, já que ela permite a adaptação a novos requisitos ou condições sem exigir uma revisão completa. O CRUD contribui para essa flexibilidade de várias maneiras:
Como as operações CRUD são fundamentais para a interação com dados, qualquer mudança nos requisitos de negócios relacionados a como os dados são gerenciados pode ser feita ajustando-se a essas operações básicas.
Os sistemas projetados em torno das operações CRUD são naturalmente mais extensíveis, pois novas funcionalidades envolvem geralmente a criação, leitura, atualização ou exclusão de dados de novas maneiras.
CRUD é usado na linguagem SQL?
Sim, CRUD é amplamente utilizado na linguagem SQL (Structured Query Language). O SQL é a linguagem padrão para gerenciamento de bancos de dados relacionais, como MySQL, PostgreSQL e SQL Server. Cada uma das operações do CRUD pode ser representada por comandos SQL específicos:
Create (Criar): Utiliza-se o comando INSERT para adicionar novos registros a uma tabela.
Read (Ler): O comando SELECT permite consultar os dados armazenados no banco.
Update (Atualizar): A modificação de dados já existentes é feita com o comando UPDATE.
Delete (Excluir): Para remover registros, emprega-se o comando DELETE.
Essas operações garantem que os dados possam ser manipulados de forma eficiente dentro de um banco relacional. No entanto, o CRUD não se restringe apenas ao SQL. Ele pode ser aplicado a diferentes tecnologias e abordagens.
Descubra como aplicar CRUD em outras tecnologias
Embora tenha sua aplicação mais conhecida no SQL, CRUD também está presente em diversas outras tecnologias. Em linguagens de programação como Python, JavaScript e Java, os desenvolvedores implementam essas operações diretamente nos sistemas, utilizando bibliotecas e frameworks que facilitam a interação com bases de dados.
Em aplicações web, por exemplo, CRUD é a base para APIs RESTful, onde cada uma das operações corresponde a métodos HTTP:
POST para criar novos registros;
GET para ler os dados existentes;
PUT ou PATCH para atualizar informações;
DELETE para excluir um recurso.
Essa abordagem garante uma comunicação eficiente entre clientes e servidores, permitindo que os sistemas sejam escaláveis e organizados. Além disso, com o avanço da computação em nuvem e do uso de serviços como Firebase e MongoDB, o CRUD se tornou ainda mais versátil, atendendo a diferentes necessidades de desenvolvimento.
Bancos de Dados Relacionais
Bancos de dados relacionais, como MySQL, PostgreSQL, Oracle e SQL Server, são estruturados em tabelas com colunas e linhas, garantindo integridade e consistência de dados. Nessas bases, o CRUD é fundamental para gerenciar os registros de maneira eficiente.
A principal vantagem dos bancos relacionais é a capacidade de manter a integridade dos dados por meio de relações bem definidas e normalização. Isso evita redundâncias e melhora a organização das informações. No entanto, para garantir a eficiência do CRUD, é necessário planejar bem o design do banco, criando índices, chaves primárias e chaves estrangeiras para otimizar as operações.
Bancos de Dados NoSQL
Os bancos de dados NoSQL, como MongoDB, Cassandra e Firebase, oferecem uma abordagem mais flexível para armazenamento de dados, permitindo a manipulação de grandes volumes de informações sem a necessidade de esquemas rígidos.
No contexto NoSQL, as operações CRUD continuam sendo essenciais, mas sua implementação varia dependendo do tipo de banco utilizado:
MongoDB (Document-Based): CRUD é realizado com comandos como insertOne, find, updateOne e deleteOne.
Cassandra (Wide-Column Store): As operações CRUD são feitas através da linguagem CQL (Cassandra Query Language), semelhante ao SQL.
Redis (Key-Value Store): A manipulação de dados ocorre através de comandos específicos como SET, GET, DEL.
A escolha entre um banco relacional e um NoSQL depende das necessidades do projeto, sendo essencial considerar fatores como desempenho, escalabilidade e consistência.
ORMs (Object-Relational Mapping)
Os ORMs são ferramentas que facilitam a implementação do CRUD, permitindo que os desenvolvedores manipulem dados utilizando código orientado a objetos, em vez de escrever consultas SQL diretamente. Exemplos populares incluem:
SQLAlchemy (Python);
Hibernate (Java);
Entity Framework (C#).
Com os ORMs, o CRUD se torna mais intuitivo e seguro, reduzindo a necessidade de escrever consultas complexas e minimizando erros comuns, como injeção de SQL.
Saiba quais são os principais desafios de implementação do CRUD
Embora o CRUD seja um conceito fundamental para a manipulação de dados, sua implementação não é isenta de desafios. O crescimento do volume de informações, a necessidade de integração com diferentes sistemas e a busca por um desempenho eficiente podem tornar essas operações mais complexas do que parecem à primeira vista.
Questões como segurança, consistência e escalabilidade exigem estratégias bem planejadas para garantir um funcionamento confiável e eficiente. A seguir, exploramos os principais desafios que podem surgir ao implementar o CRUD e como superá-los.
Performance
À medida que o volume de dados cresce, as operações CRUD podem se tornar mais lentas. Consultas mal otimizadas, falta de indexação e excesso de requisições ao banco podem comprometer o desempenho. Para mitigar esse problema, é essencial utilizar índices corretamente, otimizar as queries e empregar técnicas de cache, como Redis ou Memcached, para armazenar temporariamente resultados de consultas frequentes.
Segurança
A segurança dos dados deve ser uma prioridade em qualquer sistema que implemente CRUD. Injeção de SQL, vazamento de dados e acessos não autorizados são riscos comuns. Para evitar problemas, é essencial validar todas as entradas de usuário, utilizar parametrização em consultas SQL e aplicar controles de autenticação e autorização adequados. A criptografia de dados sensíveis adiciona uma camada extra de proteção.
Consistência de dados
Garantir que os dados estejam sempre corretos e atualizados pode ser um desafio, especialmente em sistemas distribuídos. Bancos de dados relacionais utilizam transações para assegurar a consistência, mas em ambientes NoSQL, a consistência eventual é uma abordagem comum.
Técnicas como versionamento de dados, bloqueio otimista e estratégias de reconciliação ajudam a minimizar problemas de inconsistência.
Integração
A integração do CRUD com outras partes do sistema, como front-end, APIs e serviços de terceiros, pode apresentar desafios. Diferenças entre formatos de dados, latência em requisições e compatibilidade entre tecnologias são aspectos que precisam ser considerados. O uso de padrões como REST, GraphQL e WebSockets facilita a comunicação entre os componentes do sistema.
Escalabilidade
A medida que o número de usuários e transações cresce, o sistema precisa escalar para suportar a demanda. Bancos de dados NoSQL costumam ser mais escaláveis horizontalmente, enquanto bancos relacionais exigem estratégias como sharding, replicação e balanceamento de carga. Arquiteturas baseadas em microsserviços também ajudam a distribuir a carga de trabalho de forma eficiente.
Custos
O armazenamento e manipulação de grandes volumes de dados podem gerar custos significativos, especialmente em serviços de nuvem. Estratégias como uso eficiente de índices, compressão de dados e limpeza periódica de registros obsoletos ajudam a minimizar gastos desnecessários.
A escolha do provedor de banco de dados e o modelo de precificação impactam diretamente nos custos operacionais.
Experiência do usuário
A performance do CRUD impacta diretamente na experiência do usuário. Consultas lentas e falhas de integração podem afetar a usabilidade do sistema. Para evitar problemas, é fundamental realizar testes constantes e ajustes na infraestrutura. Técnicas como pré-carregamento de dados e paginação eficiente ajudam a proporcionar uma navegação mais fluida e responsiva.
Conclusão
Em resumo, o CRUD (Create, Read, Update, Delete) é um conceito fundamental na ciência da informação e programação, especialmente quando se trata de sistemas de bancos de dados, como os baseados em SQL.
Esse conjunto de operações oferece um alicerce sólido para a gestão e manipulação de dados de forma clara e eficiente. E, embora possa parecer simples, tais operações permitem interfaces intuitivas e a capacidade de manipular dados.
A informação de hoje ajudou você a entender com clareza mais um pouco sobre a ciência de dados? Então não deixe de acompanhar o Mercado Online Digital, onde oferecemos soluções e novidades tecnológicas para usuários e empreendedores.
A programação em bloco é um novo método para programadores, considerado inovador. Leia este artigo e saiba como aprender a programar de uma maneira simplificada.
O mercado de hoje, como vemos, é inteiramente voltado para tecnologia. Seja para ajudar os outros setores da indústria, como fazem normalmente os profissionais da tecnologia da informação ou então para desenvolver novos projetos, como ocorre na programação.
Entender o básico das duas áreas, ainda que não seja obrigatório, já somam pontos extras na hora de concorrer às vagas que envolvem recursos tecnológicos. A programação é ainda mais requisitada, já que existe carência de profissionais e muita demanda.
Para os próximos anos, entender esse ofício poderá ser uma das hard skills mais requisitadas. É preciso começar logo. Mas você sabia que é possível aprender a programar de uma forma muito mais interativa? Com a Programação em Bloco é possível. Veja!
Entenda o que é a programação em bloco
Quando entramos no back-end de um site (F12 > elementos), podemos ver uma série de códigos indescritíveis para nós. Mas é claro, todos eles possuem seus significados que possibilitam até mesmo que você clique no link que te levou a este artigo. São chamados de fórmulas.
Cada uma destas fórmulas imprimem um comando que realiza uma função. Isso é programação. Embora pareça ser intraduzível, tem um conceito e um modo lógico de ser. Com a programação em bloco realizamos esta mesma tarefa, mas em uma interface muito mais interativa.
Dessa maneira criamos uma espécie de fluxograma, muitas vezes com comandos básicos a complexos e alguns deles até no idioma que você escolher. Daí vem o nome desse método, já que são criados blocos que resultam em uma ação com começo, meio e fim.
Descubra o que é possível fazer com a programação em bloco
A Programação em Bloco é muito utilizada para ensinar crianças a aprender programação. Mas ela também é indicada para qualquer pessoa que deseja entender um pouco mais como funciona essa profissão.
E, embora há quem discorde desse método, a Programação em Bloco não é menos eficaz que a forma clássica de se programar ou outras formas de se fazer isso. Mas ainda assim é recomendada por apresentar uma interface interativa e simplificada.
Com ela podemos fazer:
Aplicativos;
Jogos;
Histórias interativas;
Projetos de robótica;
Botões interativos.
Tudo isso como se estivéssemos montando uma composição em LEGO.
As vantagens da programação em bloco
As vantagens já foram discorridas neste artigo e você já deve ter em mente quais são. Mas, para ser ainda mais claro, explicamos:
A Programação em Bloco é mais econômica. Afinal, existem diversas plataformas, muitas delas online e gratuitas, que permitem aprender esse método. A mais utilizada é o Scratch, que logo iremos falar sobre ela e outras do mesmo segmento.
A Programação em Bloco é simplificada. Por oferecer um esquema baseado em blocos (como brinquedos LEGO), o programador pode criar comandos baseado em palavras simples como “abrir”, “fechar”, “piscar”, e em cores hierárquicas.
A Programação em Bloco é multilíngue. A programação clássica possui apenas um idioma universal: o inglês. Na programação em blocos é possível programar em qualquer idioma que esteja hospedado na plataforma.
A Programação em Bloco é open source. Dá para realizar downloads e uploads do conteúdo programado e implementá-los em vias mais complexas e até na programação clássica.
Blocos X métodos tradicionais
Em ambos os métodos há vantagens e desvantagens. Enquanto na Programação em Blocos possuímos as vantagens acima, nos métodos tradicionais a maior vantagem é que a aplicação é mais universal e é o que as empresas do setor buscam.
Mas em contrapartida, os métodos tradicionais, principalmente durante o estudo, não oferecem uma atuação tão sólida quanto a Programação em Blocos. Uma vez que com ela podemos realizar tarefas que já podem ser aplicadas em um computador real e não apenas um fluxograma básico.
A Programação em Bloco é a melhor maneira para entender como a prática da programação funciona antes de se transportar para o método clássico que é bem mais complexo e o ensino muito mais teórico.
Melhores plataforma de programação em bloco
Agora veja quais são as plataformas de Programação em Bloco mais utilizadas por crianças e adultos:
Scratch
É a principal plataforma de Programação em Blocos. A interface parece um jogo de tetris, bem como um LEGO. Utiliza de linguagem simples e onde cada cor dos blocos é uma categoria de ação. Além do mais, está disponível em português e muitos outros idiomas.
O Scratch é gratuito, online, simples, amigável e possui uma comunidade com mais de 11 milhões de programadores. É também Open Source, ou seja, o conteúdo pode ser encaminhado para outras plataformas de programação.
Blockly
O Blockly é uma linguagem de programação criada pelo Google. Sua aplicação é gratuita e também de código aberto. Ou seja, pode ser usado em outras plataformas. Mas diferente do Scratch, o Blockly é ainda mais moderno, trazendo uma interface mais esperta para o aluno.
Sendo assim, é possível ter uma introdução sobre a estrutura das fórmulas programadoras e começar a moldar a ideia de como programar em C# e Java.
MIT APP Inventor
O app desenvolvido pela Google e que hoje é administrado pelo MIT (Instituto Tecnológico de Massachusetts), é uma forma de programação em bloco de código aberto que permite criar aplicativos para smartphones.
Apesar de gratuito, o acesso requer um Gmail. Além do mais, não possui versão em português no momento. Mas a interface permanece simples e amigável de se navegar.
Swift Playgrounds
Criada pela Apple, a Swift Playgrounds também é voltada para o desenvolvimento de aplicativos. É um pouco mais complexo que as plataformas anteriores, mas mantém sua interatividade. A diferença dessa plataforma é que possibilita upar seus apps na App Store.
Link Unavailable
Embora algumas plataformas promissoras tenham surgido ao longo dos anos, nem sempre suas informações estão amplamente disponíveis ou acessíveis ao público. Isso pode ocorrer por mudanças nas políticas de acesso, falta de atualizações ou até mesmo descontinuação de determinados serviços.
Ainda assim, é sempre válido explorar novas ferramentas e conferir se alguma plataforma menos conhecida pode oferecer recursos inovadores para facilitar o aprendizado da programação em blocos.
CodeCombat
O CodeCombat é uma plataforma que transforma o aprendizado da programação em uma experiência semelhante a um jogo de aventura. Os usuários assumem o papel de personagens que precisam avançar por diferentes fases, resolvendo desafios com comandos de programação. O diferencial do CodeCombat é que ele permite uma transição gradual dos blocos visuais para linguagens reais, como Python e JavaScript. Isso ajuda os alunos a assimilarem a lógica da programação enquanto se divertem, tornando o processo muito mais envolvente.
MakeCode
Desenvolvido pela Microsoft, o MakeCode é uma plataforma que oferece suporte tanto para programação em blocos quanto para linguagens baseadas em texto. Ele é amplamente utilizado na educação tecnológica, permitindo que os alunos programem dispositivos como o micro:bit, além de oferecer integração com o Minecraft Education Edition.
Com uma interface intuitiva e uma abordagem prática, o MakeCode incentiva o aprendizado experimental, onde os alunos podem testar códigos e ver os resultados imediatamente, tornando o ensino mais dinâmico e acessível.
Entenda por que a programação em blocos é adequada para crianças
O mundo está cada vez mais digital, e as crianças de hoje nasceram em um ambiente onde a tecnologia faz parte da rotina. Ensinar conceitos de programação desde cedo pode parecer desafiador, mas a programação em blocos torna esse aprendizado muito mais acessível, divertido e envolvente.
Com essa abordagem, os pequenos conseguem desenvolver habilidades essenciais enquanto criam, experimentam e solucionam problemas de maneira intuitiva.
Aprendizagem divertida e envolvente
Aprender a programar pode parecer algo complexo, mas quando isso acontece por meio da programação em blocos, o processo se transforma em uma experiência lúdica. Em vez de precisar memorizar códigos e comandos, as crianças trabalham com blocos coloridos que se encaixam como peças de um quebra-cabeça.
Esse formato visual facilita a compreensão e torna tudo mais divertido, estimulando a curiosidade e o desejo de explorar novas possibilidades.
Essa abordagem permite que as crianças aprendam no próprio ritmo. Como não há uma pressão para decorar sintaxe ou comandos complicados, os pequenos conseguem se concentrar em compreender os conceitos básicos da programação em blocos sem frustrações. Isso contribui para uma experiência de aprendizado mais positiva e motivadora.
Desenvolvimento de habilidades de resolução de problemas
Resolver desafios é parte fundamental da programação em blocos. Cada atividade exige que a criança pense em soluções para alcançar um objetivo específico. Se um personagem precisa se mover para a direita, por exemplo, é necessário encaixar os blocos na sequência correta. Esse processo ajuda no desenvolvimento do pensamento crítico e na capacidade de analisar problemas de maneira estruturada, habilidades essenciais para qualquer área da vida.
Outro benefício é que os pequenos aprendem a errar sem medo. Na programação em blocos, os erros fazem parte do processo e servem como uma oportunidade para testar novas possibilidades. Isso incentiva a persistência e ensina que, para alcançar um objetivo, é preciso tentar diferentes abordagens até encontrar a solução ideal.
Aumento da criatividade
Com a programação em blocos, não existem respostas únicas. Cada criança pode criar seu próprio caminho para resolver desafios e desenvolver projetos personalizados. Seja criando animações, jogos ou histórias interativas, esse tipo de programação permite que os pequenos soltem a imaginação e expressem suas ideias de forma única. Quanto mais exploram, mais aprendem e descobrem novas maneiras de inovar.
A programação em blocos incentiva a experimentação. As crianças podem testar diferentes combinações de blocos para ver como cada alteração impacta o projeto final. Essa liberdade criativa contribui para um aprendizado mais dinâmico e engajador, fazendo com que os pequenos se sintam motivados a continuar explorando novas possibilidades.
Treino em lógica e sequências
A lógica computacional é uma habilidade essencial para qualquer pessoa que deseja entender melhor a tecnologia. Com a programação em blocos, as crianças aprendem, na prática, como organizar ações em uma sequência lógica para alcançar um resultado. Esse tipo de pensamento sequencial é aplicado em diversas áreas, desde matemática até planejamento estratégico em qualquer profissão.
Esse tipo de raciocínio ajuda a desenvolver a capacidade de estruturar ideias de maneira clara e eficiente. A programação em blocos ensina os pequenos a pensar de forma organizada e a planejar suas ações antes de executá-las, o que é útil tanto no contexto educacional quanto na vida cotidiana.
Resultados rápidos
Uma das grandes vantagens da programação em blocos é que os resultados aparecem imediatamente. As crianças podem ver na tela o efeito de cada comando que adicionam ao projeto, o que torna o aprendizado mais motivador. Esse feedback instantâneo incentiva a experimentação e a busca por soluções melhores, promovendo um ciclo contínuo de aprendizado e aperfeiçoamento.
Isso também é importante para manter o interesse dos pequenos, já que a possibilidade de ver rapidamente o impacto de suas ações torna a programação em blocos uma experiência interativa e estimulante. Quanto mais resultados positivos conseguem alcançar, mais confiantes ficam em suas habilidades.
Construção de confiança
A tecnologia pode parecer intimidadora para muitas crianças, mas a programação em blocos ajuda a quebrar essa barreira. Conforme vão resolvendo desafios e criando projetos próprios, elas ganham mais confiança em suas habilidades e percebem que são capazes de transformar ideias em realidade. Esse sentimento de conquista impulsiona o interesse pela programação e pode até despertar o desejo de aprofundar os conhecimentos no futuro.
A programação em blocos ensina valores importantes, como a paciência e a resiliência. Quando algo não sai como esperado, os pequenos aprendem a revisar suas ações, identificar o erro e tentar novamente. Isso os ajuda a encarar desafios de forma mais positiva e a desenvolver uma mentalidade de crescimento.
Programação em blocos + Scratch + I Do Code
Se tem um nome que se destaca quando o assunto é programação em blocos, esse nome é Scratch. Criado pelo MIT, o Scratch é uma das plataformas mais populares para quem quer começar nesse universo. Com uma interface amigável e cheia de recursos, permite que as crianças programem jogos, animações e histórias interativas de forma intuitiva.
Outra ferramenta interessante é o I Do Code, que oferece uma abordagem lúdica para ensinar programação em blocos. Com desafios envolventes, a plataforma estimula o aprendizado progressivo e ajuda no desenvolvimento das habilidades mencionadas anteriormente.
Saiba quem criou a programação em blocos
O conceito da programação em blocos foi desenvolvido por Mitchel Resnick e sua equipe no MIT Media Lab, responsáveis pela criação do Scratch. A ideia surgiu para tornar a programação mais acessível e menos intimidadora, especialmente para crianças e iniciantes.
Desde então, várias outras plataformas adotaram esse modelo, ampliando o alcance dessa metodologia de ensino.
Conclusão
A programação já se tornou a profissão do futuro e está em crescimento massivo. Quem quer colher frutos promissores em alguns anos, deve começar já. Principalmente os mais jovens, que precisarão cada vez mais migrar para a área da tecnologia.
Dessa maneira tem sido um bom momento para aprender programação com simplicidade. Daí vem as plataformas de Programação em Blocos, que trazem uma interface visual interativa e simples de desenvolver. Permitem a criação de animações e até mesmo apps.
E o melhor de tudo é que prepara o estudante para formas mais complexas de programação com um repertório muito mais diversificado.
Descubra como a modelagem de sistemas pode transformar projetos complexos em soluções simples, eficientes e bem planejadas.
Em um mundo cada vez mais conectado, onde empresas e pessoas dependem de soluções eficientes e bem estruturadas, a modelagem de sistemas se torna um verdadeiro pilar para quem busca desenvolver projetos com segurança, clareza e eficácia.
Se você está começando a se aventurar nesse universo ou já ouviu falar, mas ainda não entendeu totalmente o que significa e por que é tão importante, vem comigo que a gente vai conversar sobre isso de forma simples e direta.
A modelagem de sistemas nada mais é do que o processo de representar de maneira visual, lógica e detalhada como um sistema funciona ou como ele deve funcionar.
Imagine que você vai construir uma casa. Antes de sair comprando tijolo e cimento, o arquiteto faz uma planta detalhada, certo? A modelagem de sistemas segue o mesmo princípio, só que aplicada a softwares, processos de negócios, fluxos de trabalho e até mesmo à estrutura de uma organização.
Ela ajuda a organizar as ideias, entender o que precisa ser feito, quais são os recursos necessários, como as partes do sistema vão se comunicar e como os usuários vão interagir com ele. Por isso, a modelagem de sistemas é usada em áreas que vão muito além da tecnologia.
Descubra a importância da modelagem de sistemas
Muita gente só percebe a importância da modelagem de sistemas quando se depara com problemas em projetos que não foram bem planejados. Sistemas mal pensados resultam em falhas, retrabalhos, perda de tempo e dinheiro. Por outro lado, quando existe uma modelagem bem-feita, tudo flui com mais clareza.
A modelagem de sistemas ajuda a enxergar o todo e as partes ao mesmo tempo, antecipando problemas, definindo caminhos e mostrando como cada etapa deve acontecer. Ela é uma ferramenta poderosa para a comunicação entre as equipes. Afinal, não adianta o programador entender uma coisa, o gerente de projeto outra e o cliente imaginar algo totalmente diferente. Com a modelagem, todos visualizam o mesmo cenário.
Outro ponto importante: a modelagem de sistemas facilita a manutenção futura, porque, com um projeto bem documentado, qualquer pessoa que precise trabalhar nesse sistema depois consegue entender como ele foi construído.
Confira os desafios da modelagem de sistemas
Claro que, como qualquer processo, a modelagem de sistemas também tem seus desafios. O primeiro deles é o entendimento completo do problema que precisa ser resolvido. Muitas vezes, o cliente ou a empresa sabem o que querem como resultado final, mas não conseguem descrever exatamente o que é preciso.
Outro desafio é escolher a abordagem certa. Existem diferentes métodos e ferramentas para fazer a modelagem de sistemas, como diagramas UML, BPMN, fluxogramas e mapas mentais. Cada projeto pode exigir um tipo específico de modelagem, e saber qual usar faz toda a diferença.
É preciso atenção aos detalhes. A modelagem de sistemas precisa ser precisa, sem deixar lacunas. Se faltar alguma etapa ou conexão, o projeto inteiro pode sofrer lá na frente. E, claro, manter a modelagem sempre atualizada conforme o projeto evolui é essencial, e nem sempre fácil.
Veja as aplicações práticas da modelagem de sistemas
Você sabia que a modelagem de sistemas está presente em diversas áreas além do desenvolvimento de software? Pois é! Embora muita gente associe esse conceito apenas ao mundo da tecnologia, ele vai muito além. Vamos dar uma olhada em como ela aparece em diferentes contextos?
Desenvolvimento de Software
Talvez a aplicação mais conhecida da modelagem de sistemas seja no desenvolvimento de software. Antes de escrever qualquer linha de código, é importante entender o que o sistema vai fazer, como os dados vão fluir, quais são as regras de negócio, e como o usuário vai interagir com a plataforma.
Com a modelagem de sistemas, é possível criar diagramas que mostram essas interações, facilitando o trabalho dos desenvolvedores, designers e até do cliente, que consegue visualizar o que será entregue.
Na engenharia de processos, a modelagem de sistemas ajuda a entender como os processos funcionam dentro de uma empresa. Seja uma linha de produção, um processo logístico ou o atendimento ao cliente, é possível mapear todas as etapas, identificar gargalos e encontrar formas de melhorar.
Com uma boa modelagem de sistemas, é mais fácil automatizar processos, integrar setores e garantir que tudo funcione de maneira sincronizada.
Planejamento Estratégico
No planejamento estratégico, a modelagem de sistemas é uma ferramenta poderosa para entender como os objetivos da empresa se conectam com as atividades do dia a dia. Por meio dela, é possível visualizar o impacto de uma decisão em diferentes áreas, prever consequências e alinhar a equipe em torno dos mesmos objetivos.
Imagine uma empresa querendo lançar um novo produto. A modelagem de sistemas ajuda a entender desde o desenvolvimento até a entrega ao cliente, passando por produção, marketing, vendas e suporte.
Gestão de Projetos
Quem trabalha com gestão de projetos sabe o quanto é difícil alinhar todas as pontas: prazos, equipe, orçamento, escopo. A modelagem de sistemas entra justamente para trazer clareza.
Com ela, é possível representar o projeto como um todo, suas fases, entregas, responsáveis e prazos. Isso não só facilita o acompanhamento do andamento, mas também ajuda a prever riscos e ajustar o planejamento quando necessário.
Análise de Processos de Negócios
A análise de processos de negócios é outra área que se beneficia muito da modelagem de sistemas. Afinal, para melhorar um processo, primeiro é preciso entender como ele funciona.
Ao criar uma modelagem de sistemas, é possível identificar etapas desnecessárias, redundâncias e problemas de comunicação entre setores. Depois, com base nessa visão, propor soluções que realmente fazem a diferença no dia a dia da empresa.
Quando uma empresa precisa implantar um sistema de gestão (ERP, CRM, etc.), a modelagem de sistemas é fundamental para garantir que o software atenda às necessidades reais e se adapte aos processos já existentes ou, se for o caso, que esses processos sejam redesenhados de forma mais eficiente.
Conclusão
Como deu pra perceber, a modelagem de sistemas é uma ferramenta poderosa e essencial em diversos contextos. Seja na criação de um novo software, na melhoria de processos internos ou na gestão de um grande projeto, ela ajuda a trazer clareza, reduzir erros e alinhar expectativas.
Por isso, investir tempo e esforço na modelagem de sistemas desde o início pode evitar muitos problemas futuros. É como planejar bem antes de começar a construir: garante que o resultado final seja funcional, eficiente e atenda exatamente ao que se espera.
Se você está envolvido em qualquer tipo de projeto, seja como desenvolvedor, gestor ou empreendedor, vale a pena dar a devida atenção à modelagem de sistemas. Com ela, as chances de sucesso aumentam, o trabalho em equipe melhora e os resultados aparecem de forma mais rápida e sólida.